1 es 读原理:
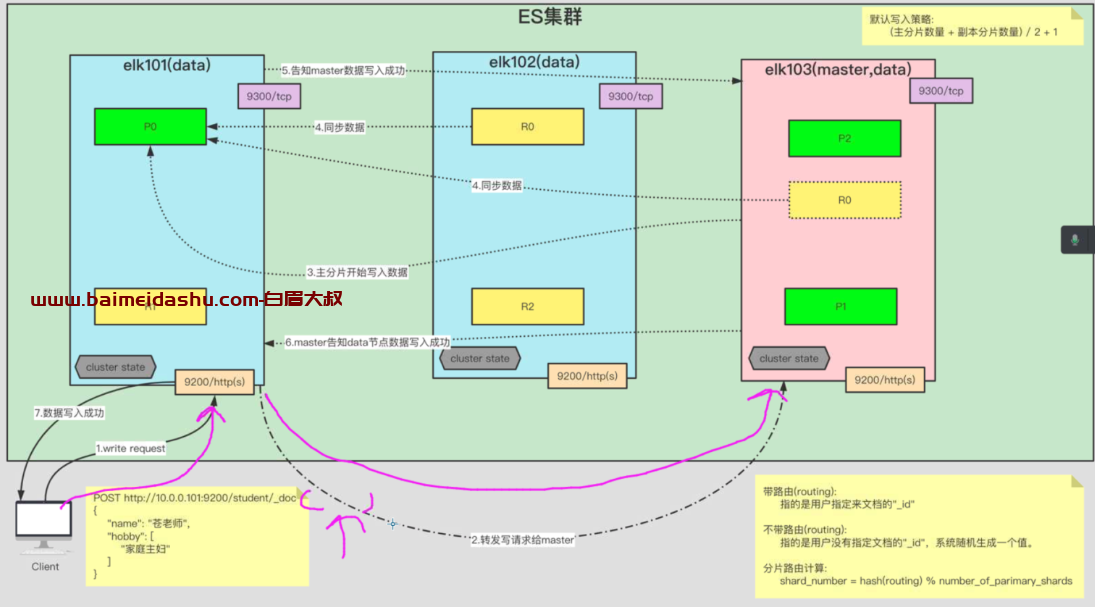
首先 客户端 发起写请求
(1)这时候 接受到强求的 节点为协调节点,
(2) 然后协调节点 转发请求 给 master节点 ,
(3) 这个时候master 节点 会根据信息 找到主分片,开始写入,
(4)写完后, 其他副本开始同步数据, (机制就是 半数以上的 同步成功就可以认为是成功了)
(5) 同步完成后 告知master 数据写入成功
(6)master 告诉 协调节点,数据写入成功。 返回给客户端了。
2. es 读过程,单个文档读取
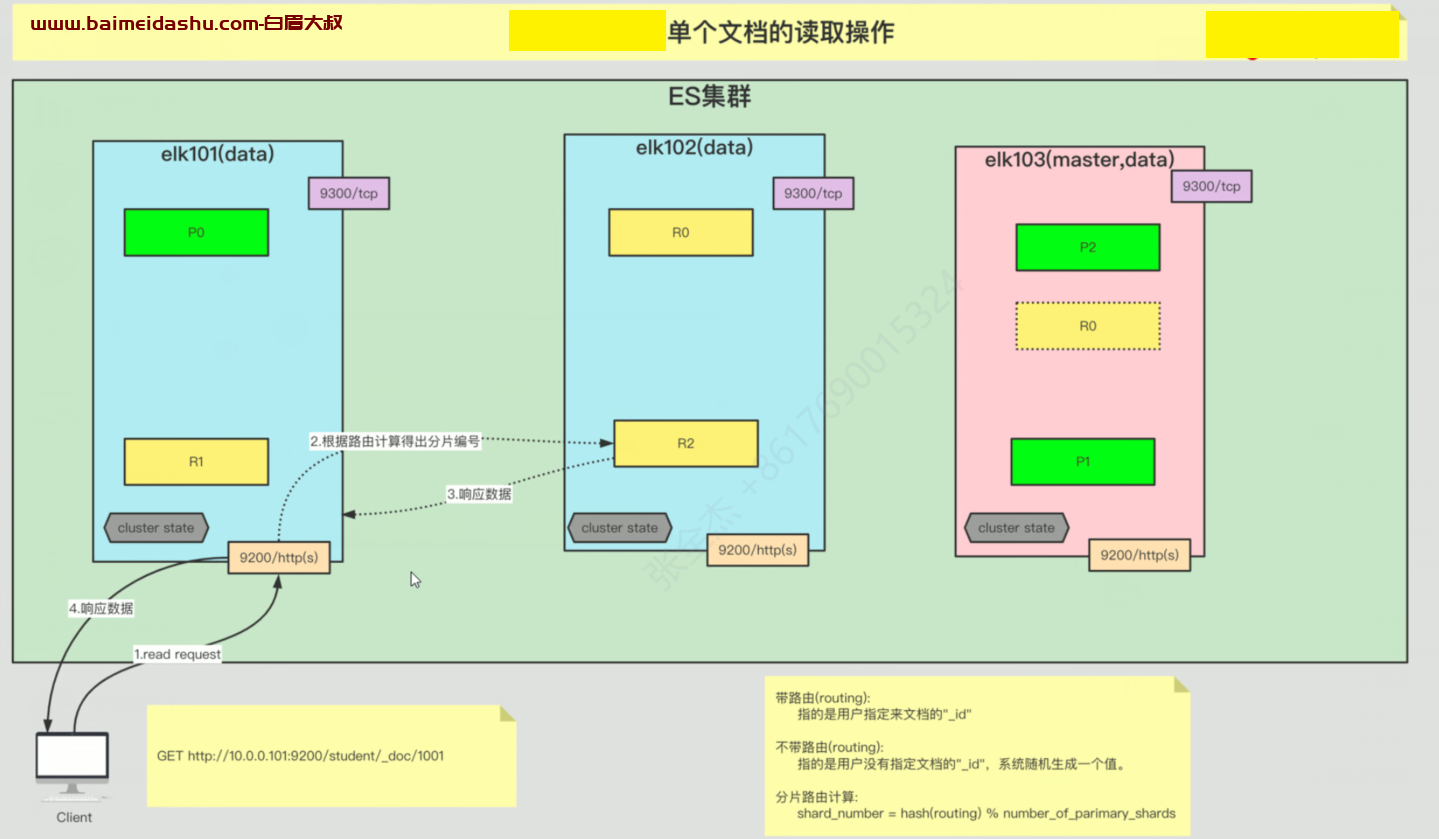
(1)首先 客户端发起读请求 (带着 id 来的)

(2) 协调节点 会根据路由算法 得出分片编号,
(这里带路由指的是 用户指定文档的_id )
不带路由,是用户没有指定Id, 系统随机生成一个值。
分片路由计算方法: shard_number = hash(routing )% number_of_praimary_shards
就是 对id hash 后 再对 主分片数量进行 取余 得到 文档所在的 分片。
(3)分片节点 得到消息就回返回给 协调节点。
(4)协调节点会给客户端发送消息,说找到了。
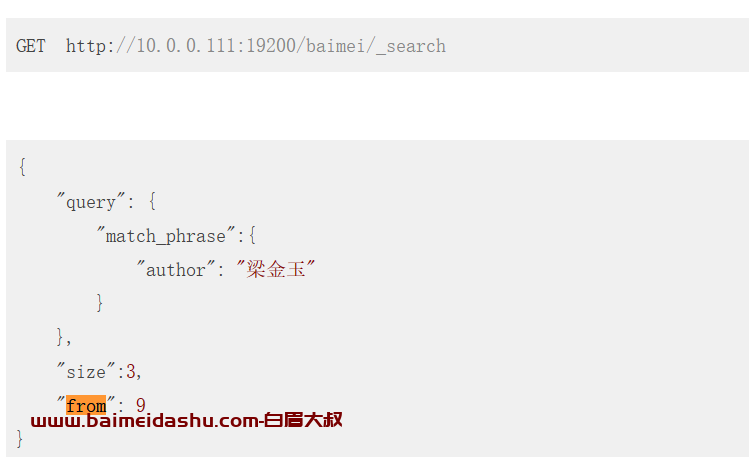
3. es 读过程 全量查询
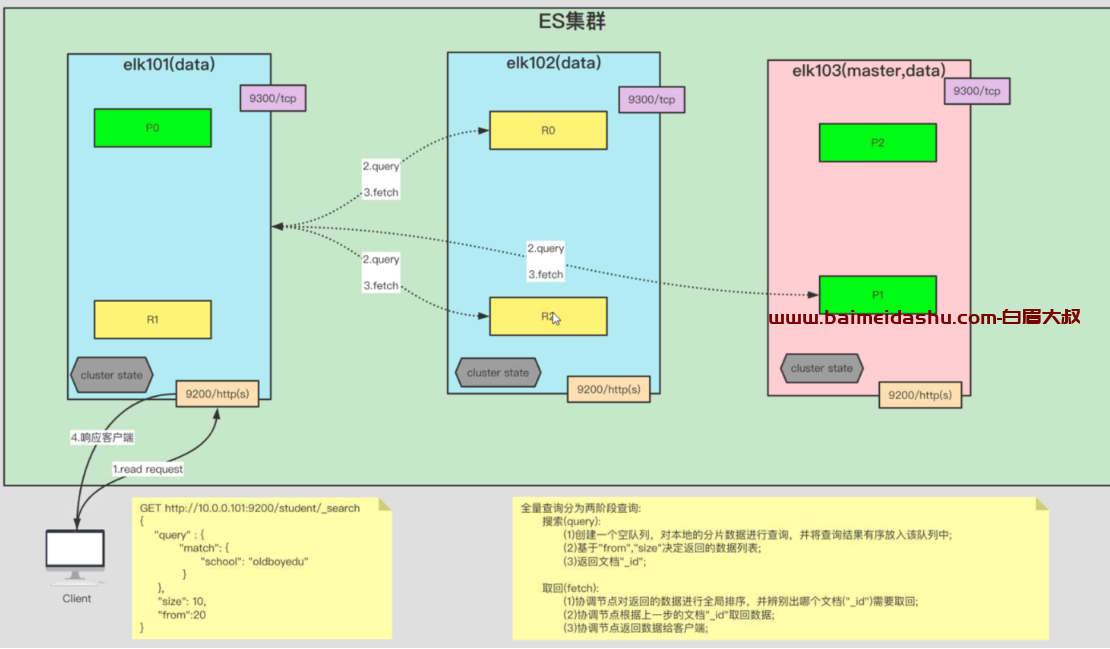
(1)客户端发起读取请求
这里是全量搜索, 我们不知道 要找到的文档, 只能是全部的分片都要去查
(2)协调节点收到请求后, 开始搜索 query
每个分片节点都要查,
首先 要创建一个空队列,对本地的分片数据进行查询,并将查询结果有序放入该队列中
然后基于“from” ,"size" 决定返回的数据列表 (这里我们举例 size 为10 )
最后, 返回文档的“id”
(3) fetch 取回
协调节点对返回的数据进行全局排序,并辨别出哪个文档id 需要取回。 (这里要注意, 每个分片都会找到 前 10个的数据,)
协调节点根据上一步的文档id 取回数据; (这里要做一个汇总, 总共从30条里再选择 10个)
然后 协调节点返回数据给客户端。
4 ES 地城存储 原理解析
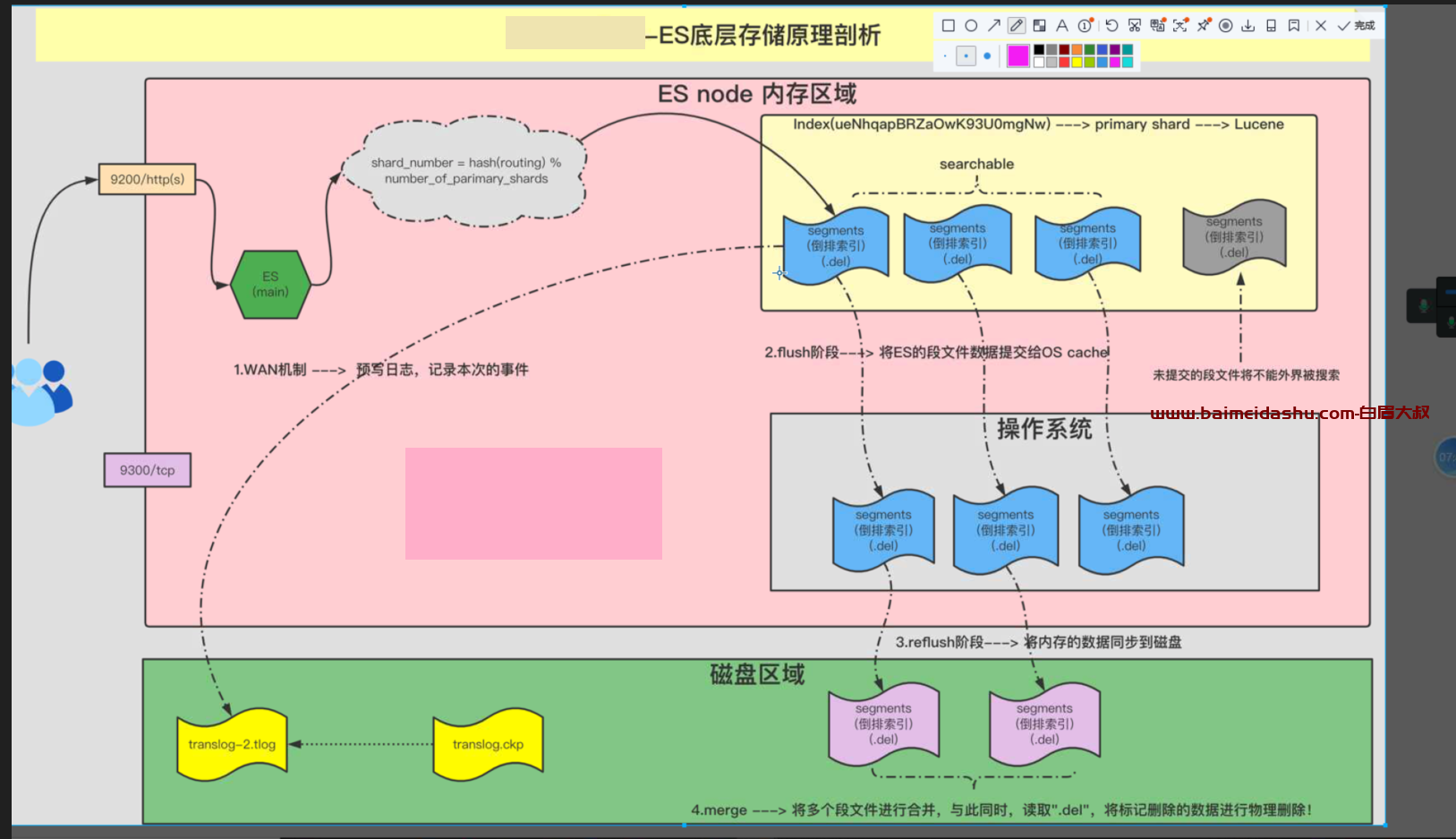
(1) WAL 机制
WAL,全称是Write-Ahead Logging, 预写日志系统
预写日志,记录本次的事件
(2) flush阶段
将ES的段文件数据提交给OS cache
同事 操作记录会记录 tarnslog-2.tlog , (如果断电, 然后重启会会读这个文件)
(3) reflush 阶段, 将内存的数据同步到磁盘
(4) merge
将多个段文件进行合并,与此同时,读取 .del ,将标记删除的数据进行物理删除 。
欢迎来撩 : 汇总all