filebeat 之filestream 模块介绍(log模块以后弃用)

在 Elastic 7.14 后 ,filestream input( log input 的后继者)为读取活动日志文件提供了更好的支持,在系统中存在背压时具有更快的反应时间、更快的注册表更新、与外部日志轮换工具的更好合作
filebeat 的 filestream 和log的区别
官方文档 翻译后的 ,勉强可读
改进的注册表性能
以前,当注册表文件(用于保存发布事件进度的文件)包含许多条目时,状态更新会变慢,即使 Filebeat 只收集少数文件。主要问题是完整的注册表在来自输出的每个 ACK 之后被序列化。这需要每次注册表写入都进行昂贵的 fsync 调用。现在,偏移量更新(offset updates)以仅追加加方式写入文件。当日志达到 10 MB 时,将注册表序列化,并减少 fsync 调用的次数。这使得注册表更新更有效。
此外,Filebeat 以前只能清理属于输入的状态。这是有问题的,因为自动发现(autodiscovery)会启动和停止新输入,从而打开新文件。这些文件的状态从未被删除。所以我们不得不分离注册表清理以从注册表中删除孤立状态。现在删除过时的条目不依赖于管道的其他部分。当一个条目被标记为无效时,无论背压或是否存在声明该文件的输入,它都会从注册表中删除。
Harvester 管理
检查需要关闭的打开文件现在与数据收集并行运行。 这样,即使系统中存在背压,输入也可以停止 havester。 此外,注册表元数据更新和条目删除不再依赖于输出的可用性,这意味着可以比以前更快地从注册表中删除过时的状态。
灵活的阅读器管道
除了改进之外,我们还添加了新功能。 现在,多行、JSON 和容器日志解析的顺序可在名为解析器的选项下进行配置。 此外,我们计划添加一个 syslog 解析器,以便你可以从以 syslog 格式编写的日志文件中提取信息。 通过使读取器管道更加灵活,我们能够在所有 Filebeat 输入中采用解析器。 我们已经将它们添加到 AWS S3 输入中,未来将支持更多输入。
更好地配合外部日志轮转工具
我们还改进了对外部日志轮换工具的支持。 前面描述的改进让 filestream input 在使用基于重命名的轮转策略时轮转事件的反应更快。 我们还为基于 copytruncate 的策略引入了一个特殊的 prospector。
以前,当使用 copytruncate 轮换输入文件时,Filebeat 无法跟踪日志。 在复制活动文件时进行轮换,Filebeat 将其作为新的日志文件处理并将内容发送到输出,这导致了重复事件。 当使用 rotation.external.strategy.copytruncate.* 选项配置时,输入现在可以正确处理旋转的文件并继续将它们转发到之前停止的地方。
我们正在计划对日志轮换进行更多增强,因为文件轮换是日志管理的重要组成部分。
使用filestream替换log类型案例:
[root@baimeidashu-elk111 /tmp]#cat /tmp/student.info
{
"name": "孙建超",
"hobby": ["抽烟","喝酒","烫头"]
}
{
"name": "王宗玉",
"hobby": ["点烟","倒酒","染发"]
}
{
"name": "杨雄",
"hobby": ["买烟","买酒","买染发膏"]
}
filebeat 配置文件
filebeat.inputs:
- type: filestream
paths:
- /tmp/student.info
# 定义解析器,解析器的执行顺序从上到下哟~
parsers:
# 进行多行匹配
- multiline:
# 指定匹配的类型
type: count
# 指定匹配的行数
count_lines: 4
# 对文本进行json格式解析
- ndjson:
# 将解析的字段放在指定的位置,""代表放在顶级字段
target: ""
# 指定要解析的字段
message_key: message
output.console:
pretty: truefilebeat -e -c /root/config/filestream/2.yaml | grep name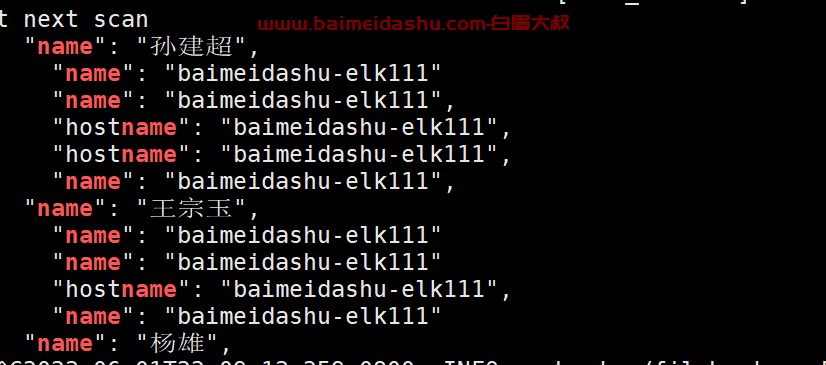
方法3:
filebeat.inputs:
- type: filestream
paths:
- /tmp/student.info
# 定义解析器,解析器的执行顺序从上到下哟~
parsers:
# 进行多行匹配
- multiline:
type: pattern
pattern: '}$'
negate: true
match: before
# 对文本进行json格式解析
- ndjson:
# 将解析的字段放在指定的位置,""代表放在顶级字段
target: ""
# 指定要解析的字段
message_key: message
output.console:
pretty: true
方法3:
filebeat.inputs:
- type: filestream
paths:
- /tmp/student.info
# 定义解析器,解析器的执行顺序从上到下哟~
parsers:
# 进行多行匹配
- multiline:
# 指定匹配的类型
type: count
# 指定匹配的行数
count_lines: 4
# 对文本进行json格式解析
- ndjson:
# 将解析的字段放在指定的位置,""代表放在顶级字段
target: ""
# 指定要解析的字段
message_key: message
output.console:
pretty: true
欢迎来撩 : 汇总all