1监听流程:
(1)首先要有一个 main() 线程
(2)在 main 线程中创建 Zookeeper 客户端,这时就会创建两个线程,一个负责网络连接通信(connet),一个负责监听(listener)
(3)通过 connect 线程将注册的监听事件发送给 Zookeeper
(4)在 Zookeeper 的注册监听器列表中将注册的监听事件添加到列表中
(5)Zookeeper 监听到有数据或路径变化,就会将这个消息发送给 listener 线程
(6)listener 线程内部调用了process()方法,主要负责 执行
2常见的监听场景有以下两项
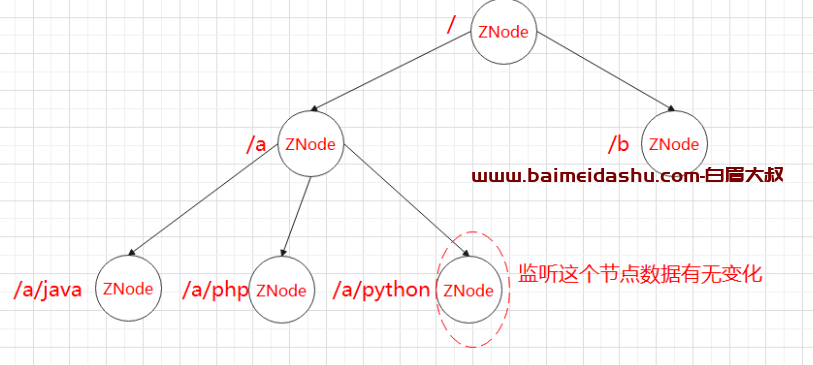
(1)监听Znode节点的数据变化
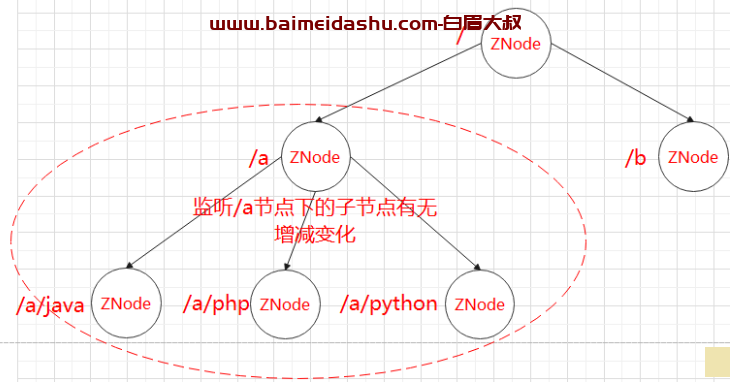
(2)监听子节点的增减变化
这里需要注意的是:
因为 ZNode 模型没有文件和文件夹的概念,每个节点既可以有子节点,也可以存储数据,而在 ZooKeeper 中,限制了每个节点只能存储小于 1 M 的数据,实际应用中,最好不要超过 1kb
为什么要这么设计呢?原因有以下几点:
ZooKeeper 为了保证写入的强一致性,会严格按照写入的顺序串行执行,某个时刻只能执行一个事务。如果上一个事务执行耗时比较长,会阻塞后面的请求
因为每个 ZooKeeper 的节点都存储了完整的数据,每个 ZNode 存储的数据越大,则消耗的物理内存也越大
因为 ZooKeeper 中每个节点都存储了 ZooKeeper 的所有数据,每个节点的状态都要保持和 Leader 一致,同步过程至少要保证半数以上的节点同步成功,才算最终成功。如果数据越大,则写入的难度也越大
欢迎来撩 : 汇总all