项目Web模块构建 python 版 : 连接
画像项目Web模块构建 java版 : 连接
画像项目拆分之mysql : 连接
先制作一个 jdk 的镜像, 后期的 组件都会在 这个jdk 镜像基础之上创建。
docker 创建基于 centos7的 jdk8的镜像 :连接
docker制作zookeeper镜像 : 连接
画像项目拆分之 springboot : 连接
画像项目拆分之 es : 连接
画像项目拆分之 hadoop : 连接
画像项目拆分之 Hive : 连接
用户画像项目运行步骤
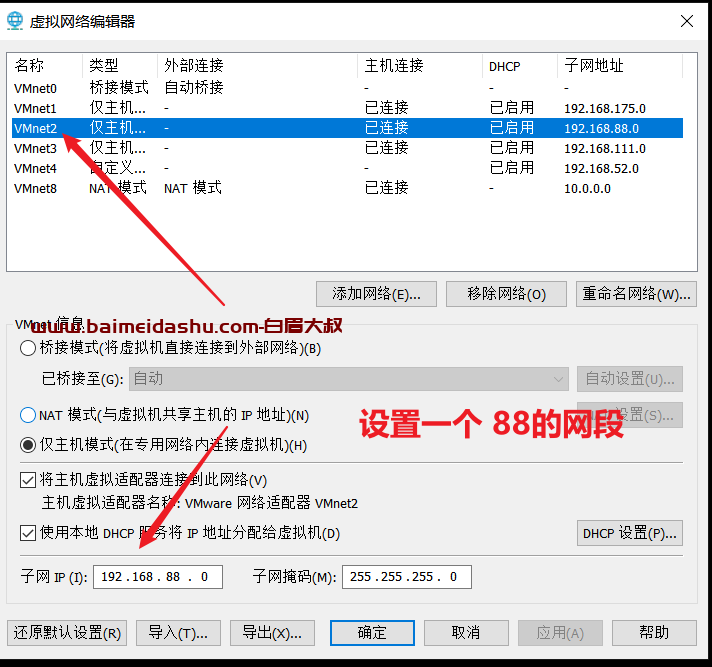
添加下面的映射
C:\Windows\System32\drivers\etc\hosts
192.168.88.166 up01虚拟机启动
-
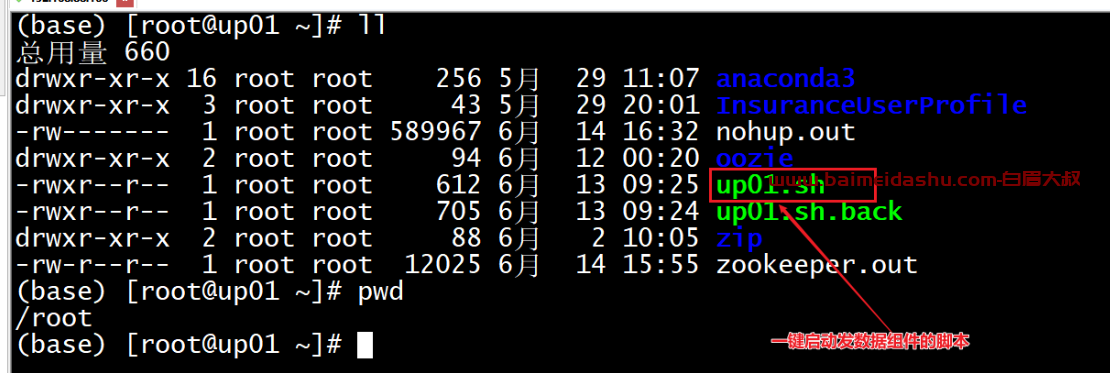
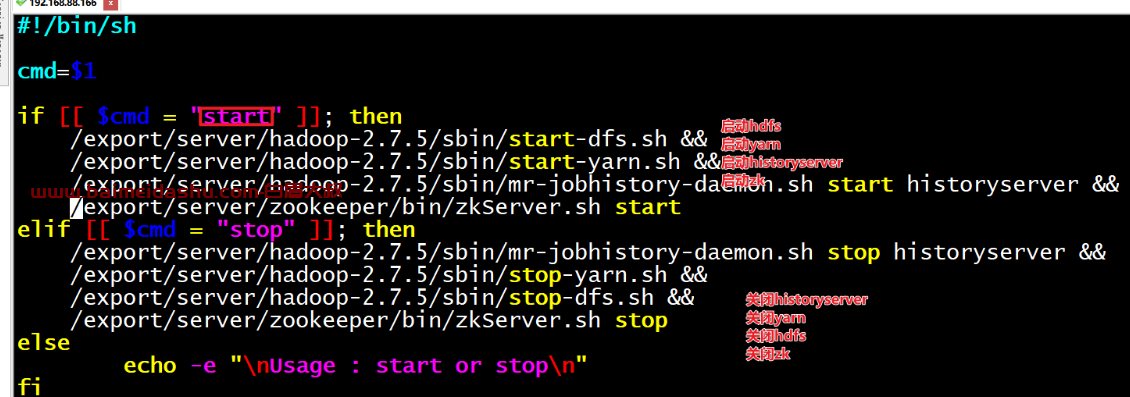
一键启动脚本,方便启动服务
一键启动脚本位置:/root/up.sh
启动命令:./up.sh start启动
停止命令:./up.sh stop停止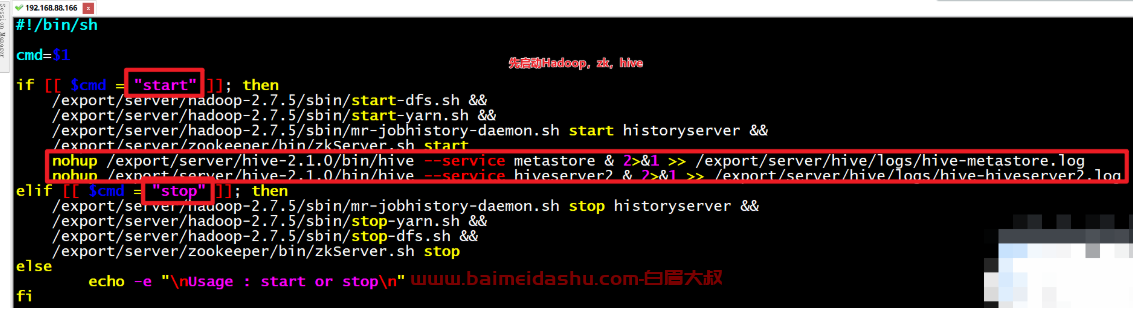
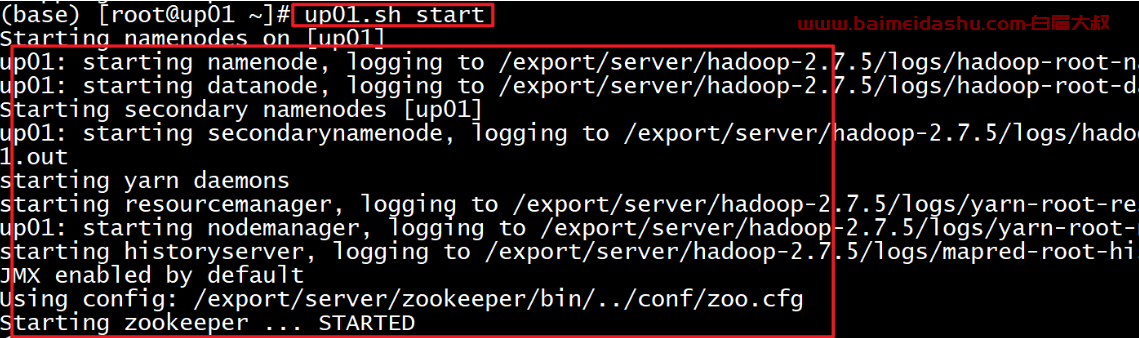
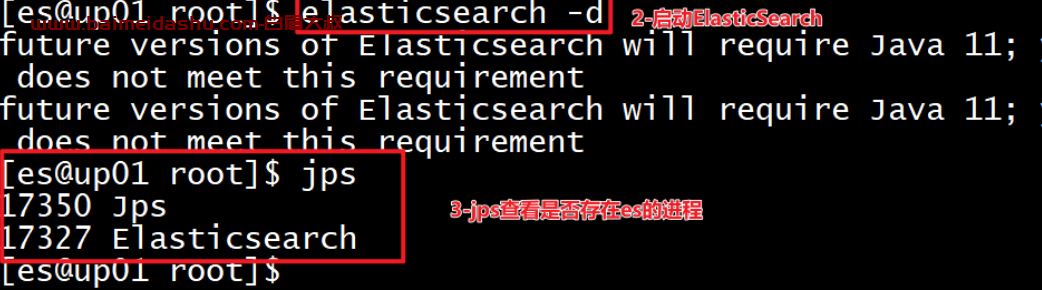
启动ES的组件,因为ES不仅仅ODS层业务数据存储,ES还承接画像结果数据写入
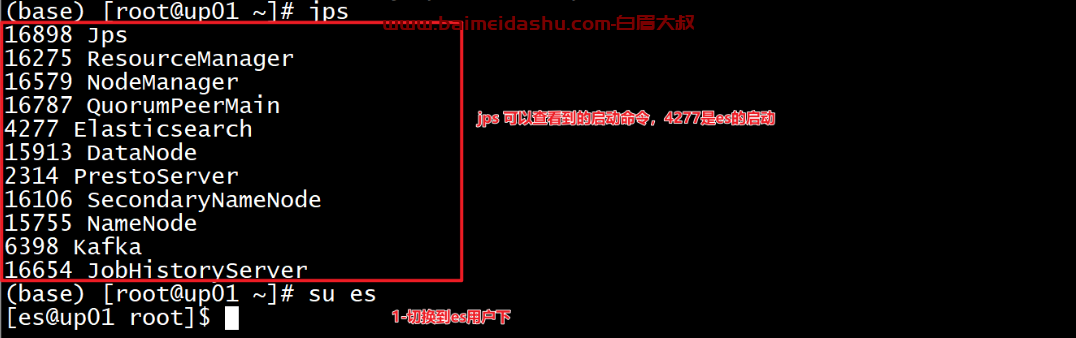
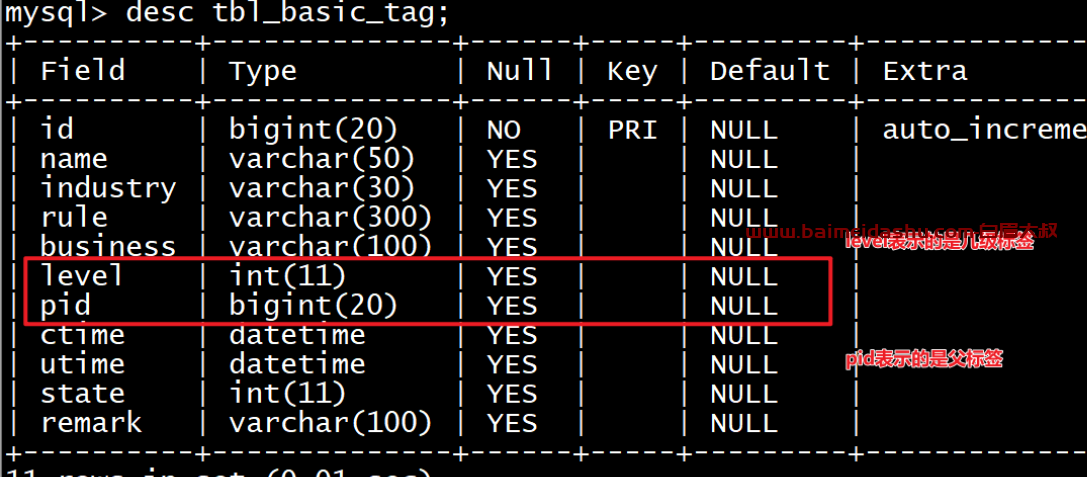
同时MySQL提供了标签体系数据
### hadoop服务启动命令 ###
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
# web ui页面
http://up01:9870/
http://up01:8088/
### hive服务启动命令 ###
nohup /export/server/hive-2.1.0/bin/hive --service metastore & 2>&1 >> /export/server/hive/logs/hive-metastore.log
nohup /export/server/hive-2.1.0/bin/hive --service hiveserver2 & 2>&1 >> /export/server/hive/logs/hive-hiveserver2.log
### zk服务启动命令 ###
zkServer.sh start
### kafka服务启动命令 ###
nohup /export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties &
### spark(yarn模式)服务启动命令 ###
/export/server/spark/sbin/start-history-server.sh
http://up01:18080/
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
${SPARK_HOME}/examples/src/main/python/pi.py \
10
### es服务启动命令 ###
su es
elasticsearch -d
#---------------------------------------------------------------------------------------------
欢迎来撩 : 汇总all