TiKV如何做到更细粒度弹性扩容(分片)
数据分片是分布式数据库的关键设计,如果要是实现扩展,从底层技术看,就是做分片,分片最重 要的区别,是在于预先分片(静态),还是自动分片(动态),传统分库分表或者分区的方案都 是预先分片,比如提前创建100个分表,属于静态分片,这种分片只解决表容量的问题,没有解 决弹性的问题。所以,第一点,我们要优先使用自动分片算法。
第二,分片总是需要一个维度和算法,比较常见是:
• 哈希(hash)
• 范围(range)
• 列举(list)
在TiKV系统里,采用了Range算法,类似“Whereage>=30”,这种范围查询在OLTP业务是非常常见场景,在
这个场景下,而Range分片可以更高效地扫描数据记录,而Hash分片由于数据被打散,扫描操作的I/O开销更大,Range分片可以简单实现自动完成分裂与合并,弹性优先,分片需要可以自由调度。
一个非常重要的概念:Region,Region是理解后续一系列机制的基础。
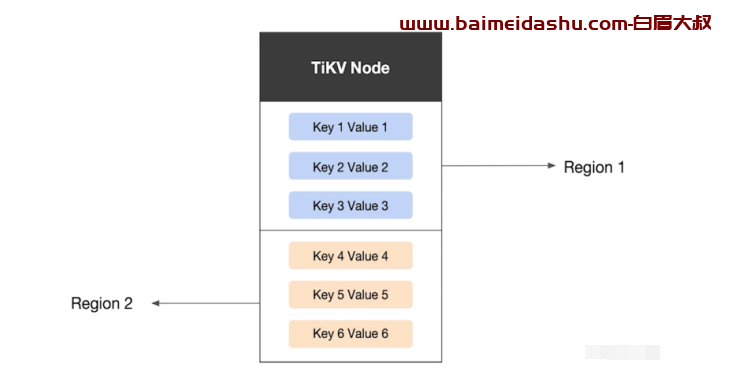
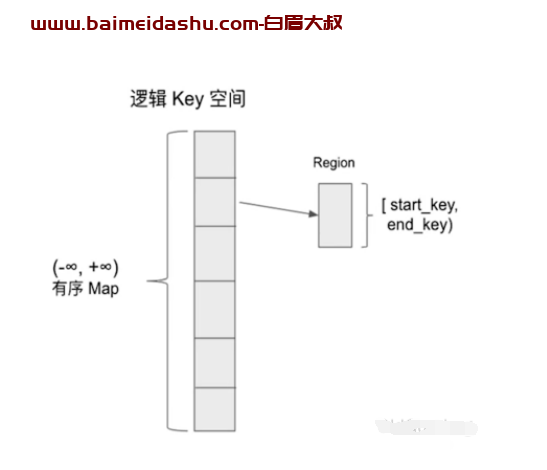
我们将TiKV看做一个巨大的有序的KVMap,我们通过range的方式,将整个Key-Value空间分成很多段,每一段是一系列连续的Key,我们将每一段叫做一个Region,并且我们会尽量保持每个
Region中保存的数据不超过一定的大小(这个大小可以配置,目前默认是96MB)。
每一个Region 都可以用StartKey到EndKey这样一个左闭右开区间来描述。
当某个Region的大小超过一定限制(默认是144MB)后,TiKV会将它分裂为两个或者更多个Region,以保证各个Region的大小是大致接近的,这样更有利于PD进行调度决策。同样的,当 某个Region因为大量的删除请求导致Region的大小变得更小时,TiKV会将比较小的两个相邻Region合并为一个。
同时为了保证上层客户端能够访问所需要的数据,我们的系统中也会有一个组件记录Region在节 点上面的分布情况,也就是通过任意一个Key就能查询到这个Key在哪个Region中,以及这个Region目前在哪个节点上。以Region为单位做数据的分散。
每个regin 相当于 一个小片, 怎么做到 高可用呢?
TiKV如何做到高并发读写
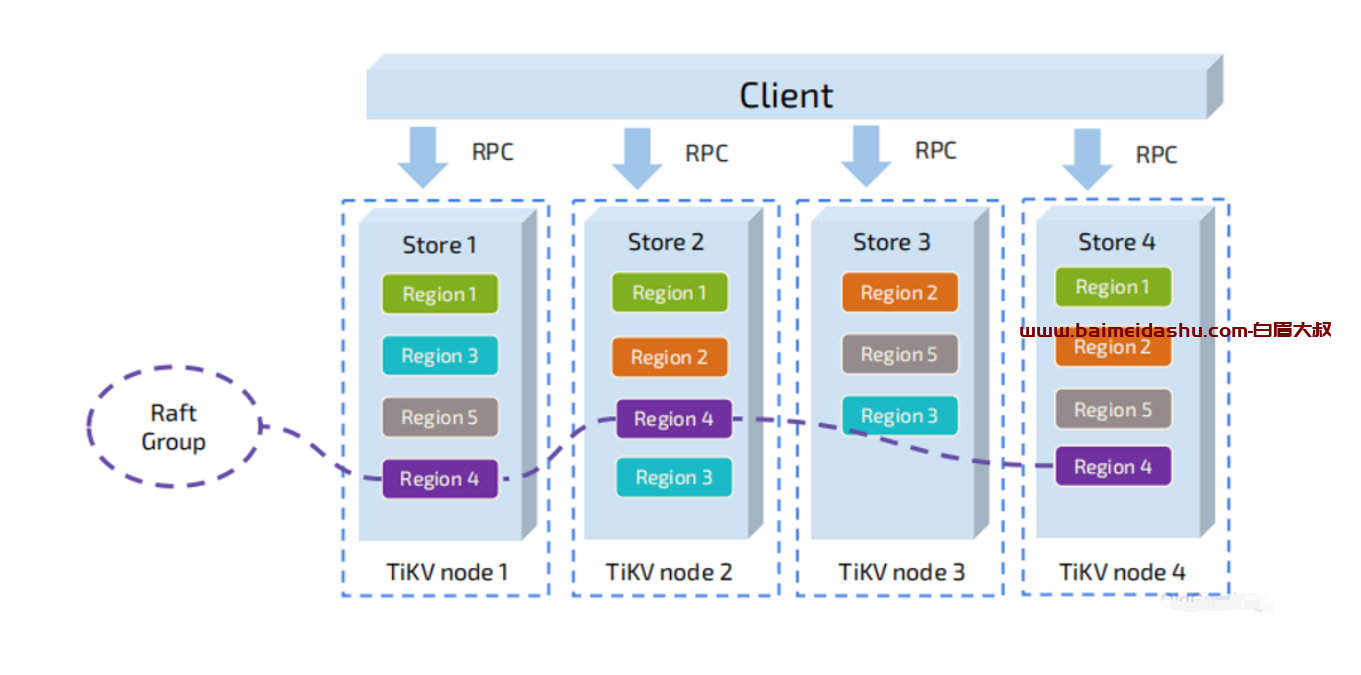
跟ES 的 分片很相似。
问题: 如果只是频繁的 读写某一个reginon, 就需要我们进行打散。 都是通过PD 来操作的, 因为PD是负责调度的, 也有 自动打散的算法。
4.4 TIDB如何保证多副本最终一致性和副本高可用

Raft算法通过先选出leader节点、有序日志等方式,简化了流程、提高效率,并通过约束减少了不确定性的
状态空间。 TIDB
相对Paxos逻辑更清晰,容易理解与工程化实现。 OCEANBASE
欢迎来撩 : 汇总all