
HDFS巡检、监控、调优
1.巡检
HDFS 为集群提供高可用性弹性存储服务,是集群的存储主体。
每日早晚巡检HDFS服务,包括HDFS服务可用性、存储使用率、datanode是否有故障盘等。
大概有如下内容:
1.HDFS 总体状态
2.HDFS 容量是否过阈值
3.HDFS UI 巡检
4.NameNode 巡检
5 .datanode 巡检参数巡检(第一次巡检需检查):文末有涉及
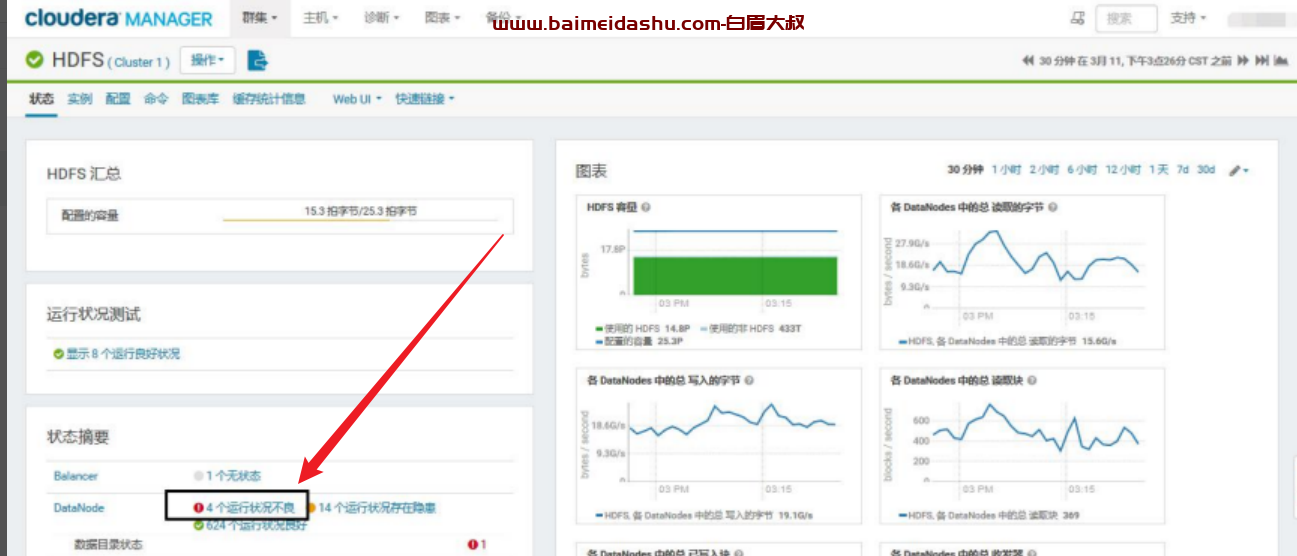
1.HDFS 总体状态
HDFS 状态,如下的红色提示需要关注

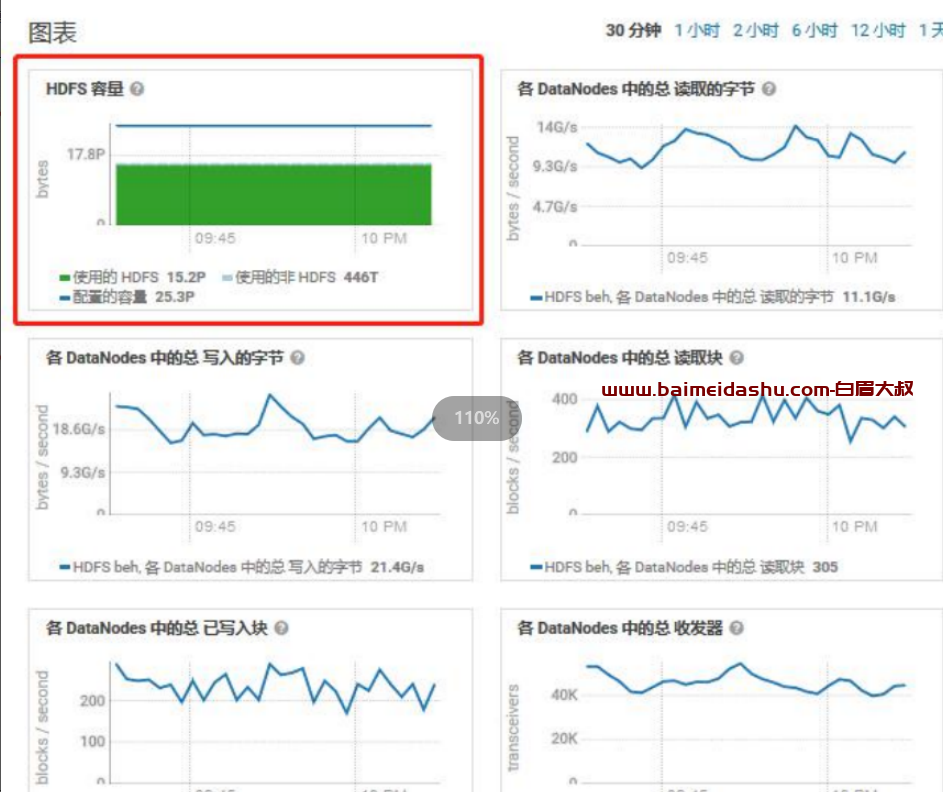
2.HDFS 容量是否过阈值
3 HDFS UI 巡检
1.Summary 巡检
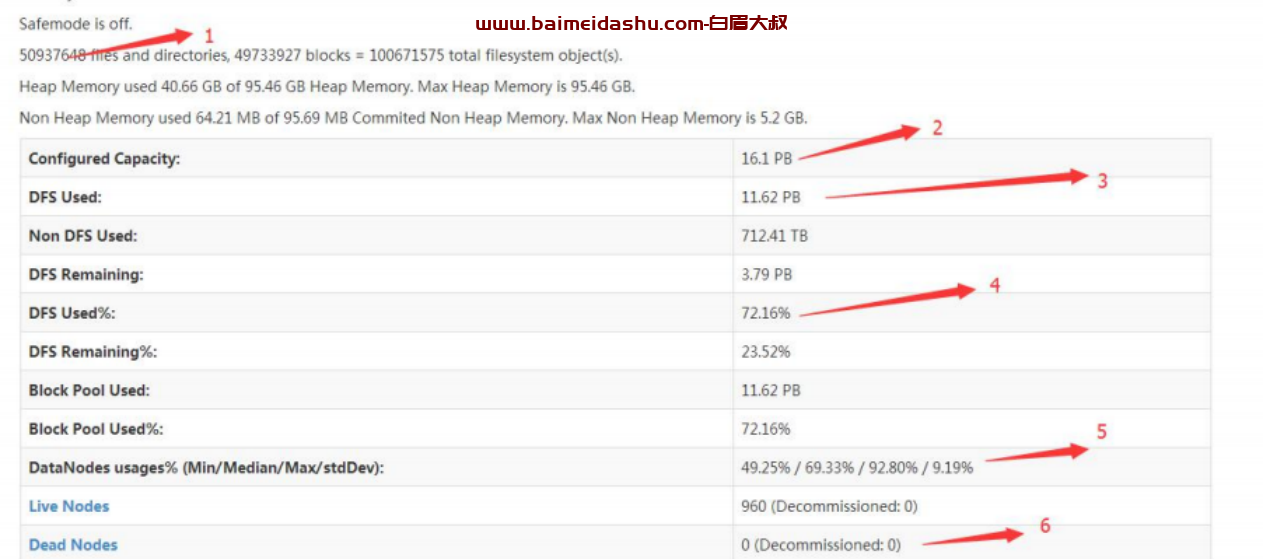
对应上图所示标号,逐一进行解释:
(1)HDFS 总文件数:此数值代表着 HDFS 存储内有多少文件,该数值的警
告阈值为 5000W
(2)HDFS 总存储容量:此数值代表 HDFS 总存储容量
(3)占用存储容量:此数值代表为占用的 HDFS 存储容量
(4)HDFS 占用比:此数值应时刻关注,警戒阈值为 75%,如有超过,应立
即告知业务侧清理数据
(5)平均占用比例:此数值代表着 HDFS 各个节点的存储使用均衡情况,若
最后一个数字高于 5%,说明此刻系统的存储均衡是不正常的,需要判断
是否有故障节点和执行 balance 操作
(6)集群内断开节点:此数值代表集群内与 hdfs 断开连接的节点,通常故障
节点,可尝试登陆该主机判断故障问题(服务挂掉,系统宕机,硬件故障
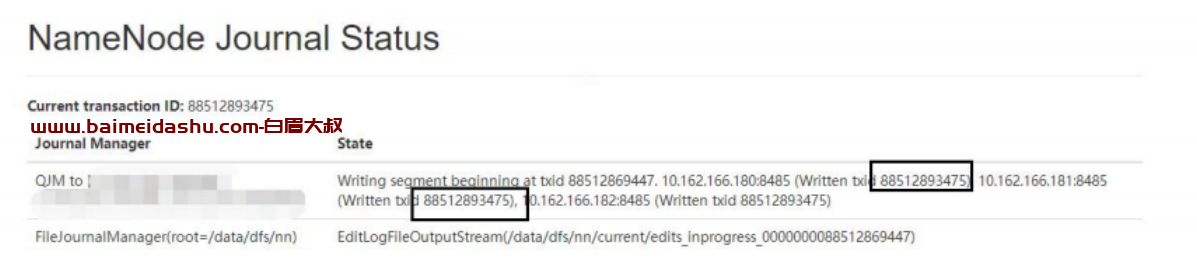
等)2.NameNode Journal Status
3.datanode Volume Failures
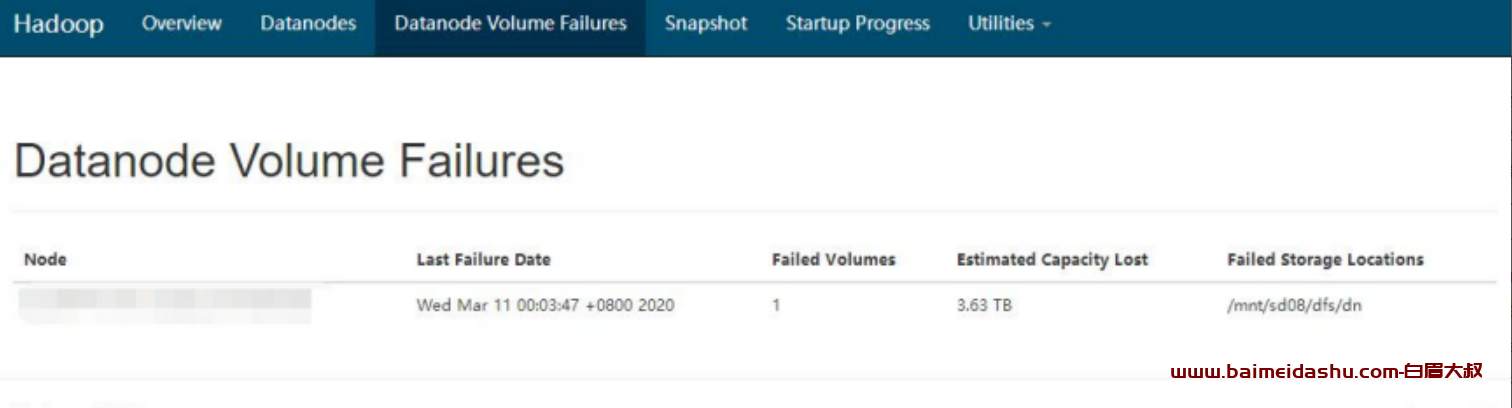
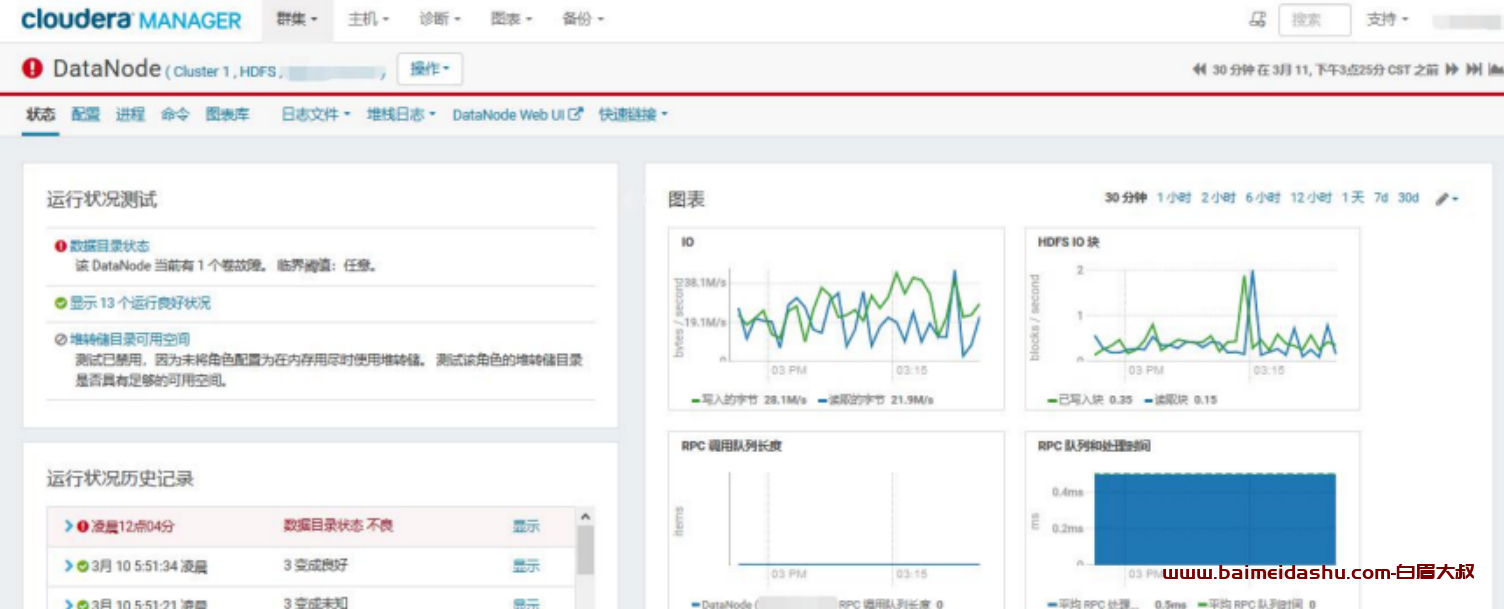
CM 中查看
3.NameNode 巡检
1.NameNode 高可用是否存活
2.NameNode 状态是否正常
3.编辑日志同步平均时间是否过高
4.RPC 队列长度是否过高、处理时间是否过高
5.JVM 堆栈内存使用情况
6.主机内存使用情况
7.磁盘延迟
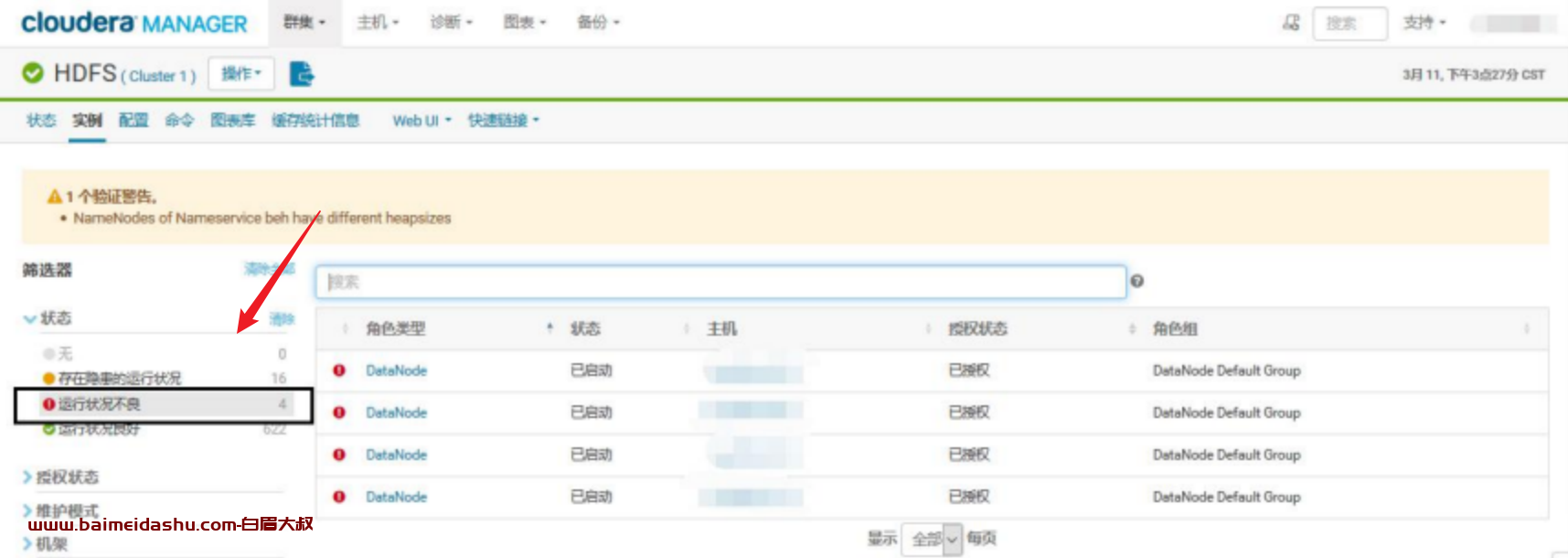
4.datanode 巡检
在 HDFS 界面顶端点击 datanodes,会出现该集群内所有 datanode 主机清单
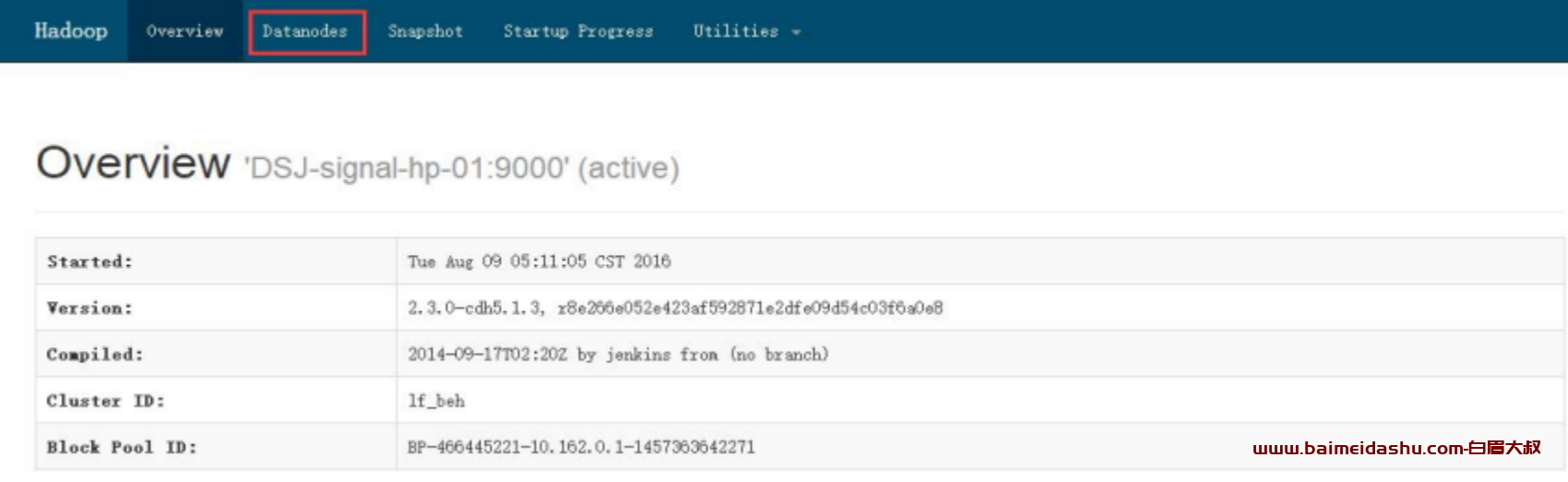
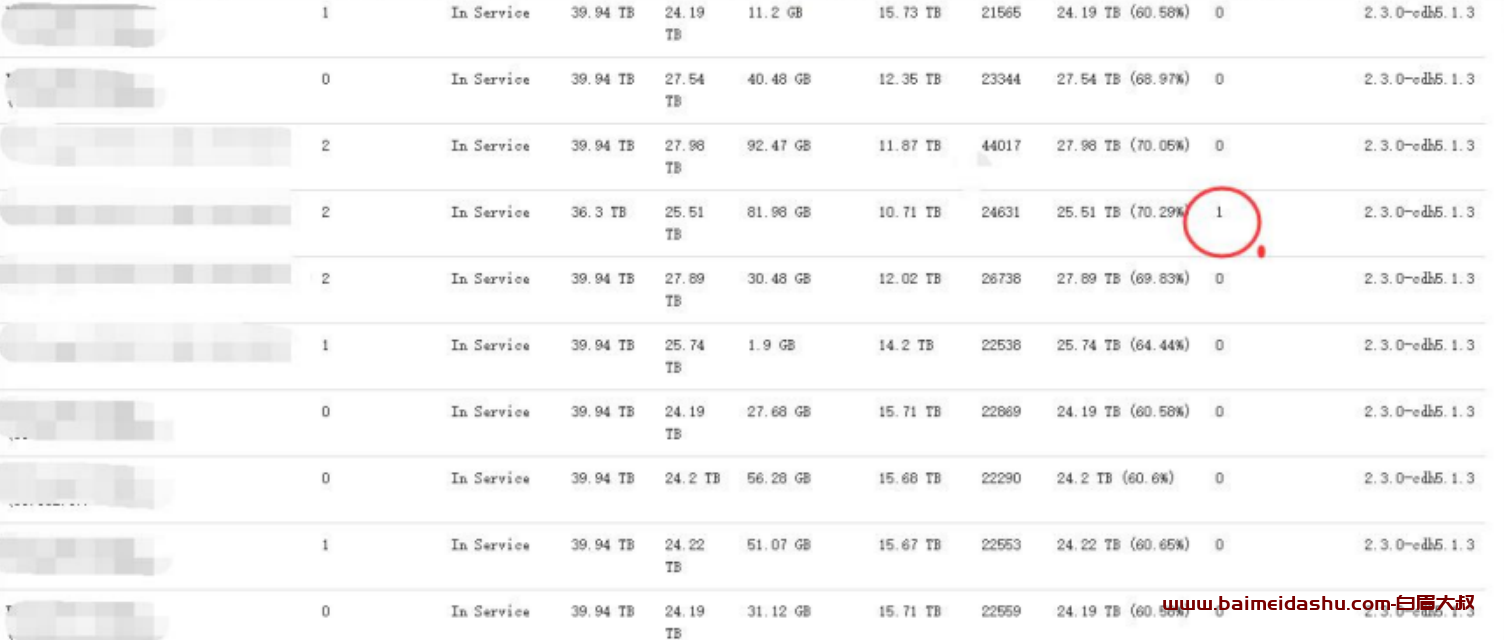
(1)上图所示圆圈部分,是代表该节点存在坏卷,有可能是文件系统损坏也
有可能是硬盘损坏,需要登录该主机进行故障判断,从而解决故障
(2)粉色部分代表该主机已经于 HDFS 断开,有可能是服务挂了,也有可能
是主机硬件故障,同样需要登录主机判断(这里与首页 Dead Node 是一
致的)
参数巡检(第一次巡检需检查)
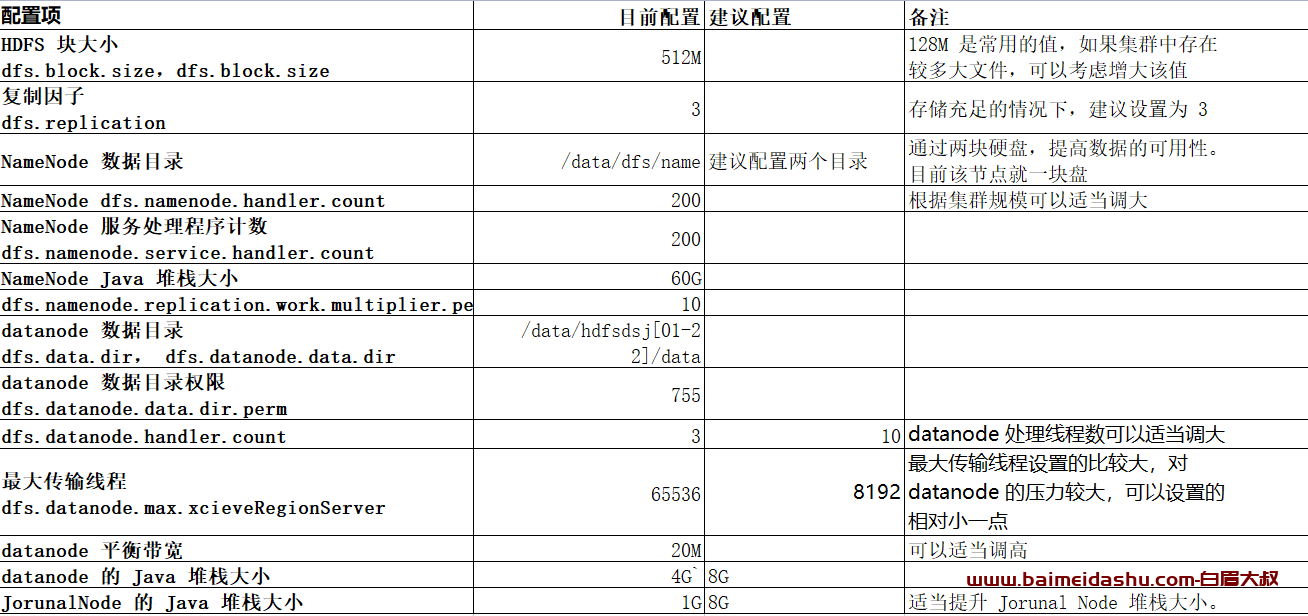
欢迎来撩 : 汇总all

