
YARN参数调优
1.节点内存资源
yarn.nodemanager.resource.memory-mbNodeManager 一般和 datanode 部署在一起,这些角色本身也要消耗内存,并且操作系统也需要部分内存,建议 Container 内存可以适当降低,这些总的内存相加不能超过节点物理内存,我们给操作系统留 5G 以内的内存
2.节点虚拟 CPU 内核
yarn.nodemanager.resource.cpu-vcoresNodeManager 可以使用的核数,我们产线环境的核数配置的跟机器的核数是一致的
3.Container 最小分配内存
yarn.scheduler.minimum-allocation-mbContainer 最小内存定义了 Yarn 可以分配给 Container 最小资源,不管任务本身处理的数据量大小,都会至少分配这么多的内存,我们产线环境设置的是2G,从目前的监控上看内存资源是够用的,CPU 资源紧张
4.Container 最大分配内存
yarn.scheduler.maximum-allocation-mbContainer 最大可申请的内存,目前我们产线环境配置的是 32G,因为我们产线环境有 Spark 作业,Spark 同一个执行器可以跑过个任务,平分内存
5.资源规整化因子
yarn.scheduler.increment-allocation-mb
假如规整化因子 b=512M,上述讲的参数
yarn.scheduler.minimum-allocation-mb 为 1024,
yarn.scheduler.maximum-allocation-mb 为 8096,然后我打算给单个 map
任务申请内存资源(mapreduce.map.memory.mb):
申请的资源为 a=1000M 时,实际 Container 最小内存大小为 1024M(小于
yarn.scheduler.minimum-allocation-mb 的话自动设置为
yarn.scheduler.minimum-allocation-mb);申请的资源为 a=1500M 时,实际得到的 Container 内存大小为 1536M,计算公式为:ceiling(a/b)*b,即 ceiling(a/b)=ceiling(1500/512)=3,3*512=1536。此处假如 b=1024,则 Container 实际内存大小为2048M也就是说 Container 实际内存大小最小为yarn.scheduler.minimum-allocation-mb 值,然后增加时的最小增加量为规整化因子 b,最大不超过 yarn.scheduler.maximum-allocation-mb
当使用 capacity scheduler 或者 fifo scheduler 时,规整化因子指的就是参数yarn.scheduler.minimum-allocation-mb,不能单独配置,即yarn.scheduler.increment-allocation-mb 无作用;
当使用 fair scheduler 时,规整化因子指的是参数yarn.scheduler.increment-allocation-mb
我们产线环境设置的是 512M
6.Container 最小虚拟 CPU 内核数量
yarn.scheduler.minimum-allocation-vcores产线环境配置的为 1
7.最大 Container 虚拟 CPU 内核数量
yarn.scheduler.maximum-allocation-vcores我们的产线环境配置的是 12
8.MapReduce ApplicationMaster 的内存
yarn.app.mapreduce.am.resource.mb我们产线环境设置的是 2G,2G 基本够用了,如果有特殊情况,可以酌情改大
9.ApplicationMaster Java 最大堆栈
通常是 yarn.app.mapreduce.am.resource.mb 的 80%,1.6G
10.Map 任务内存
mapreduce.map.memory.mb
Map 任务申请的内存大小,产线环境设置的是 2G,一般有作业覆盖
11.Reduce 任务内存
mapreduce.reduce.memory.mb
Reduce 任务申请的内容大小,产线环境设置的是 2G,一般有作业覆盖
12.Map 和 Reduce 堆栈内存
mapreduce.map.java.opts、mapreduce.reduce.java.opts以 map 任务为例,Container 其实就是在执行一个脚本文件,而脚本文件中,会执行一个 Java 的子进程,这个子进程就是真正的 Map Task,mapreduce.map.java.opts 其实就是启动 JVM 虚拟机时,传递给虚拟机的启动参数,表示这个 Java 程序可以使用的最大堆内存数,一旦超过这个大小,
JVM 就会抛出 Out of Memory 异常,并终止进程。而mapreduce.map.memory.mb 设置的是 Container 的内存上限,这个参数由 NodeManager 读取并进行控制,当 Container 的内存大小超过了这个参数值NodeManager 会负责 kill 掉 Container。
在后面分析
yarn.nodemanager.vmem-pmem-ratio 这个参数的时候,会讲解NodeManager 监控 Container 内存(包括虚拟内存和物理内存)及 kill 掉Container 的过程。
也就是说,mapreduce.map.java.opts 一定要小于
mapreduce.map.memory.mb
mapreduce.reduce.java.opts 同 mapreduce.map.java.opts 一样的道理。
默认是 mapreduce.map.memory.mb 和 mapreduce.reduce.memory.mb的 80%
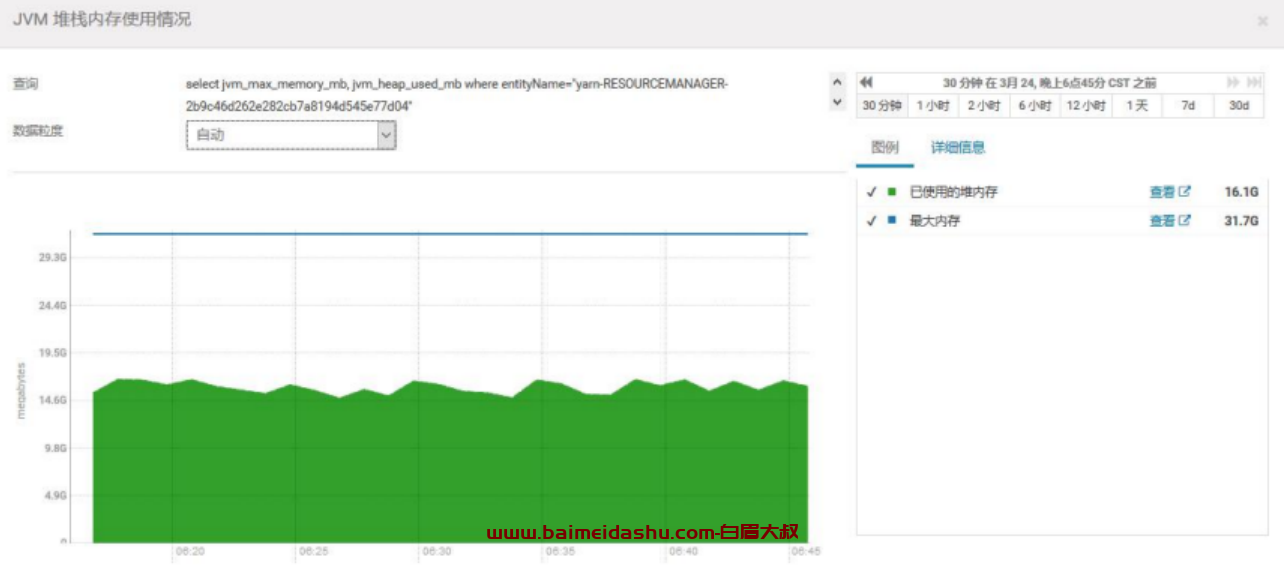
13.ResourceManager 的 Java 堆栈大小
产线环境配置的是 32G,-Xmx32768m产线环境使用了 16G
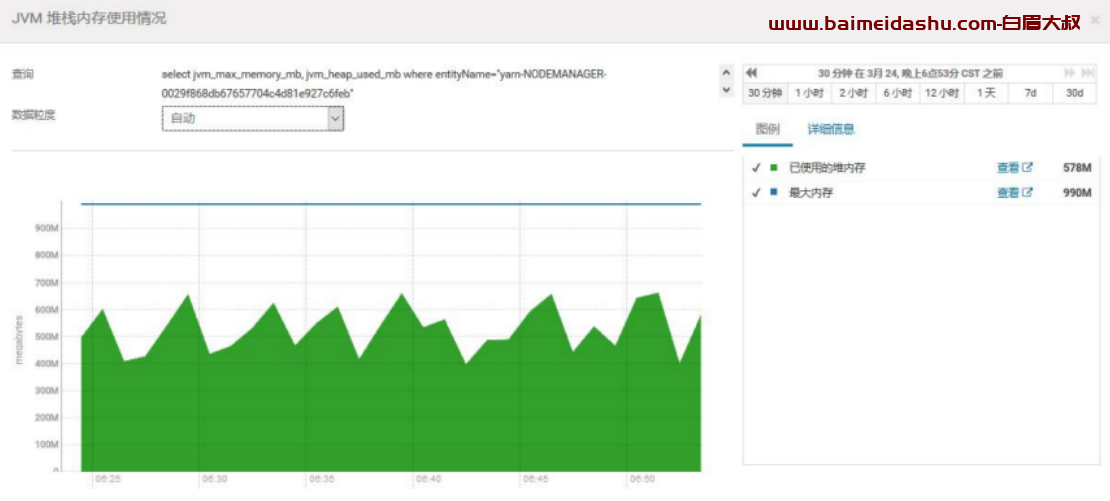
14.NodeManager 的 Java 堆栈大小
产线环境配置的是 1G,-Xmx1024m对于节点数较大,并且处理任务较多的集群,NodeManager 的内存可以相应设置的充裕一些,比如 2G-4G
15.Reduce 任务前要完成的 Map 任务数量
mapreduce.job.reduce.slowstart.completedmaps该参数决定了 Map 阶段完成多少比例之后,开始进行 Reduce 阶段,如果集群空闲资源较多,该参数可以设置的比较小,如果资源紧张,建议可以设置的更大,由 0.8 改为 0.95
欢迎来撩 : 汇总all

