
HBase 巡检
HBase 是使用 HDFS 作为底层存储的 NoSQL 数据库,提供了满足实时性和随即读写功能的数据库服务。
每日早晚巡检 HBase 服务,检查各集群的 HMaster 和 RegionServer 状态,是否事务积压等问题。
1.查看 CM HBase 的整体状态
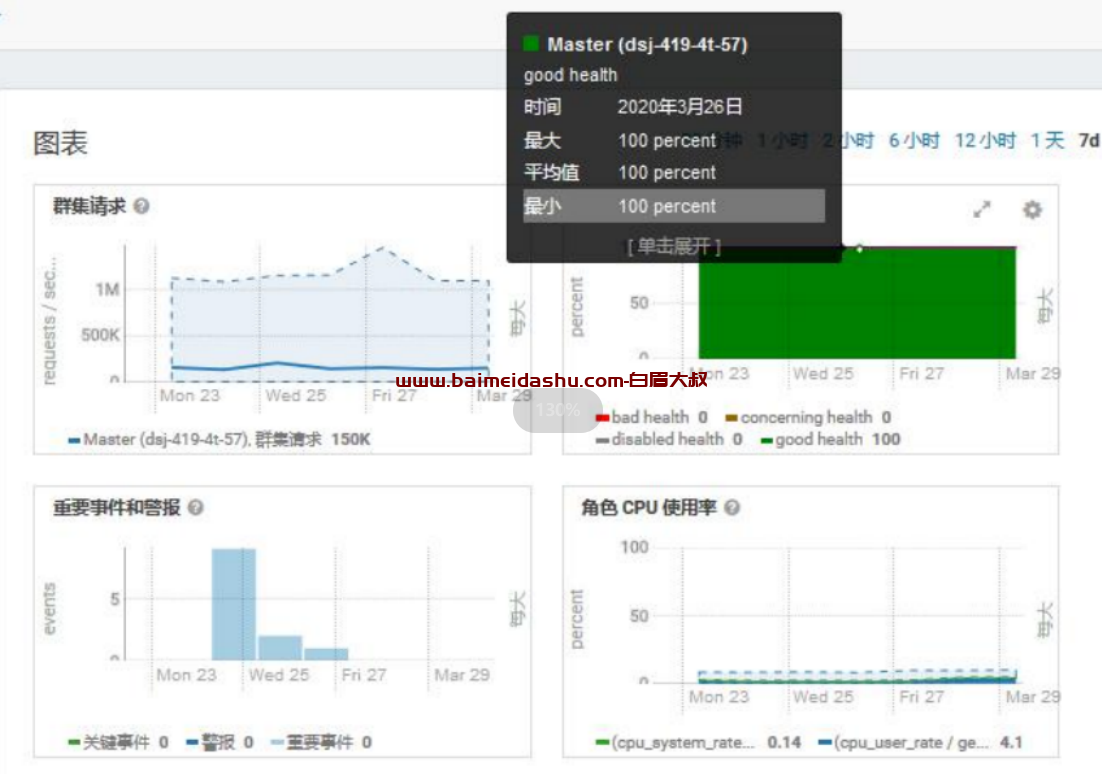
1.HBase 的状态,目前看没有严重警告
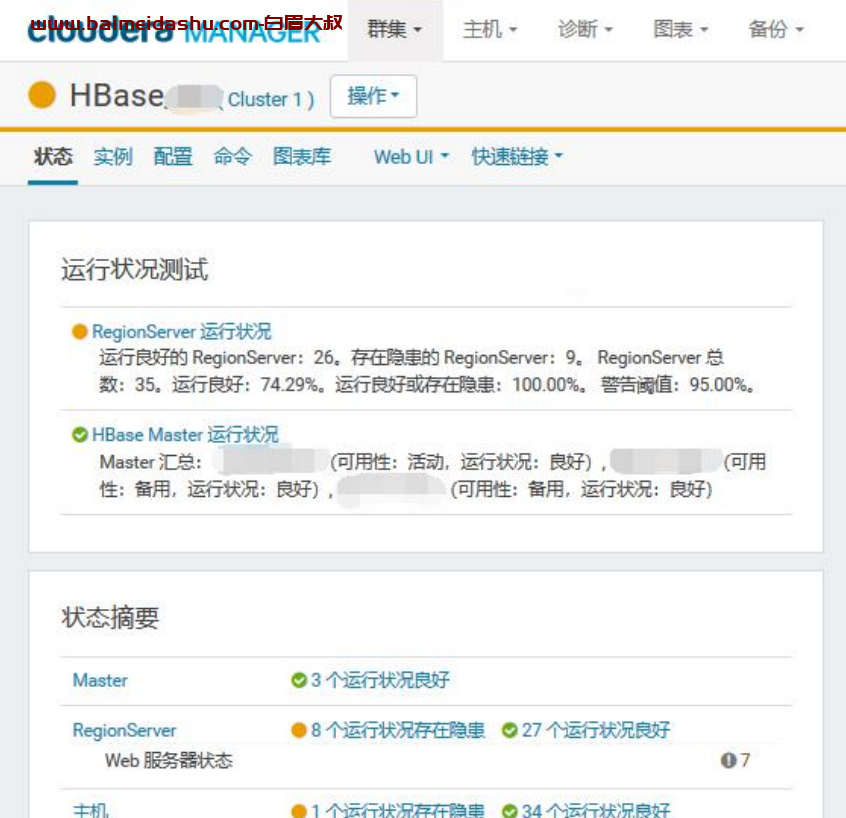
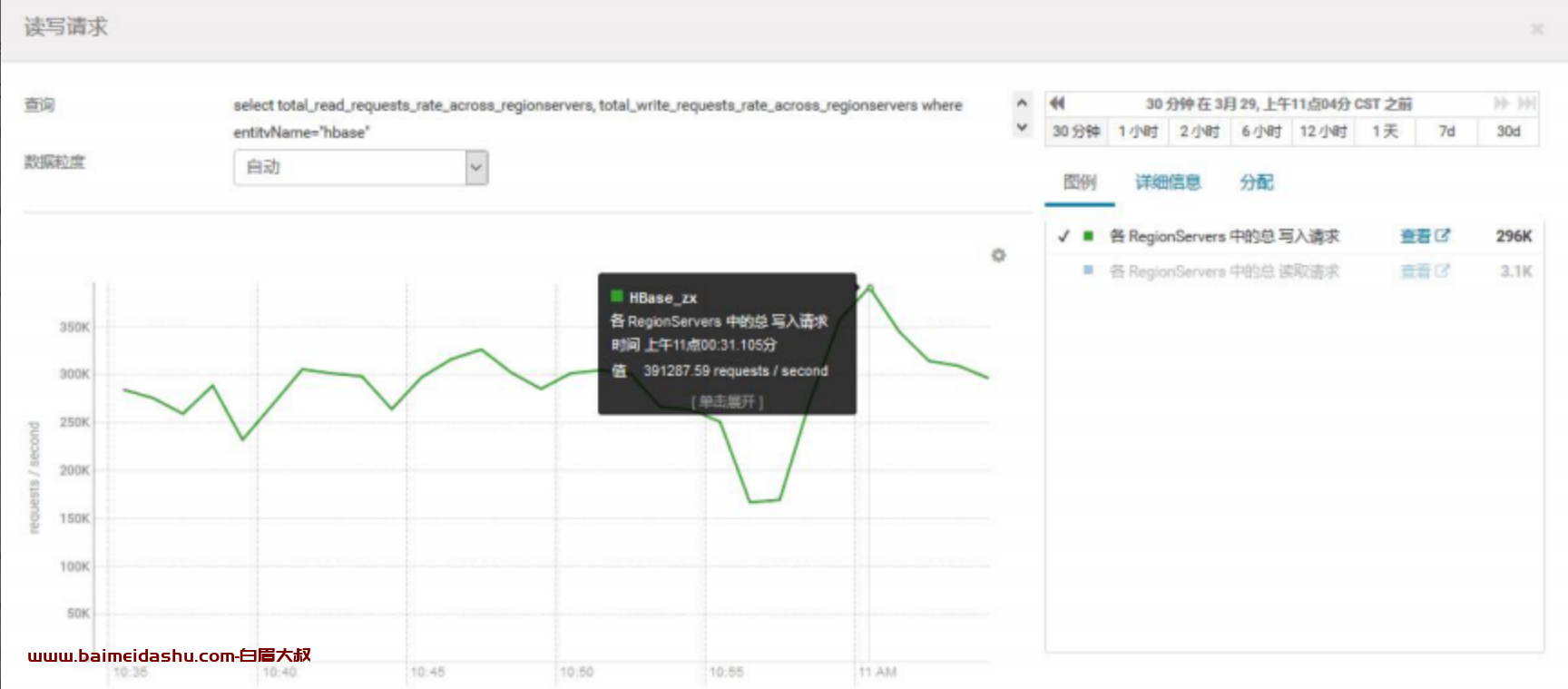
2.查看集群读写请求量

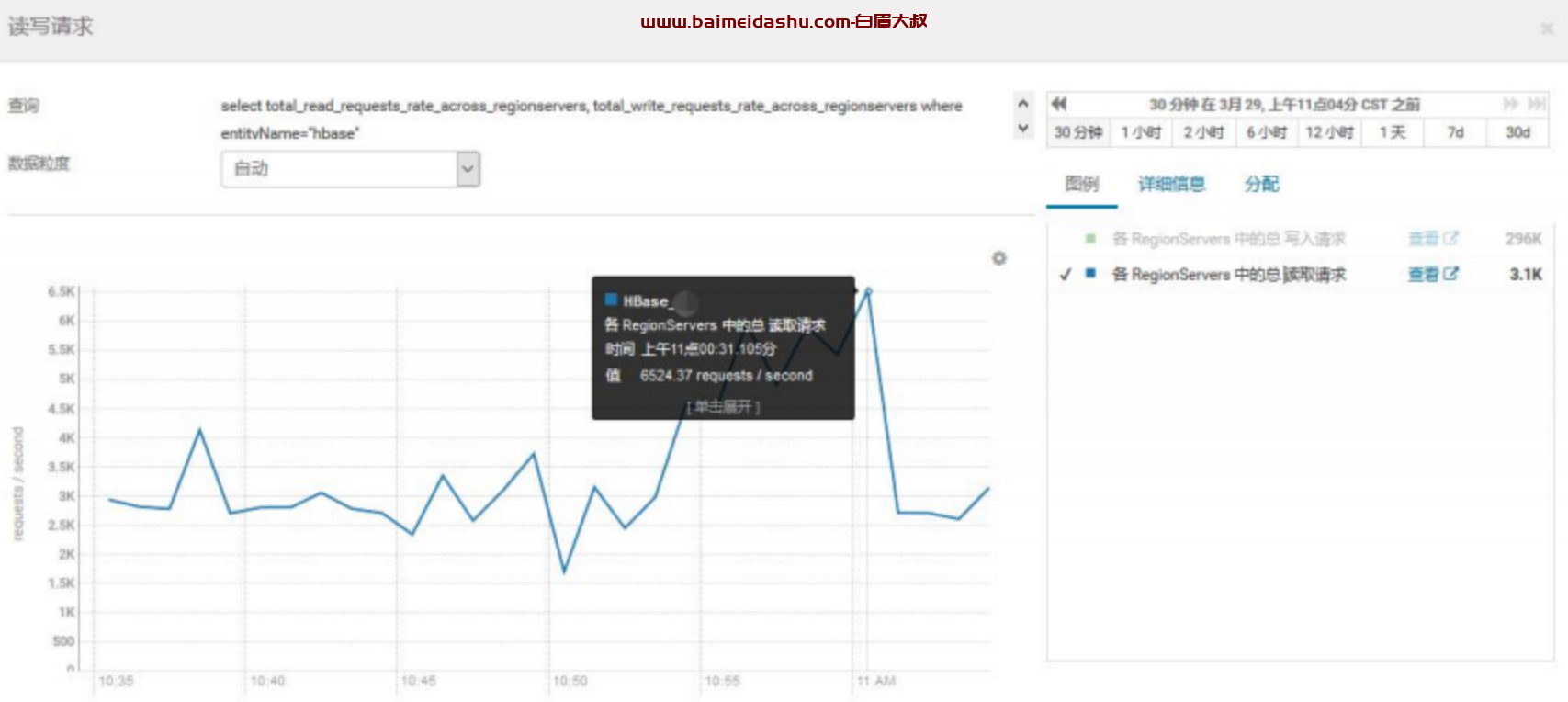
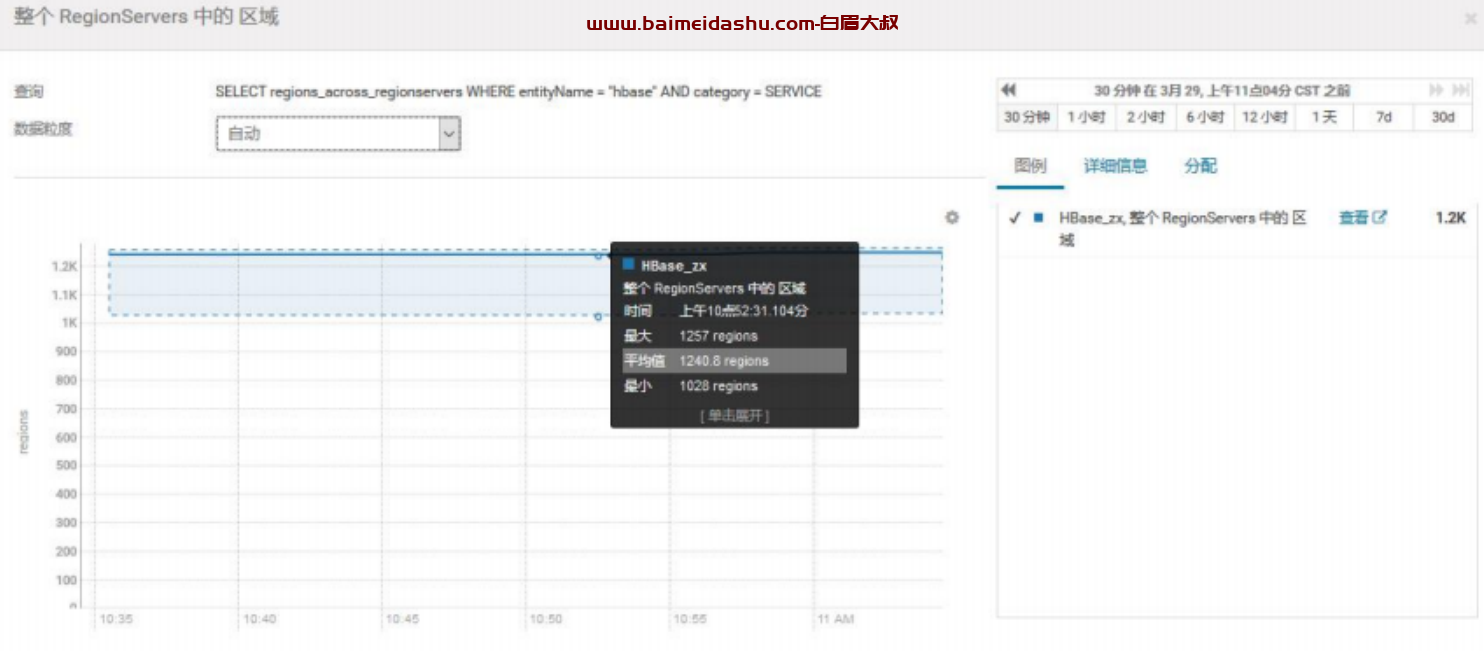
3.查看总 Region 数,有 4 万+的 Region
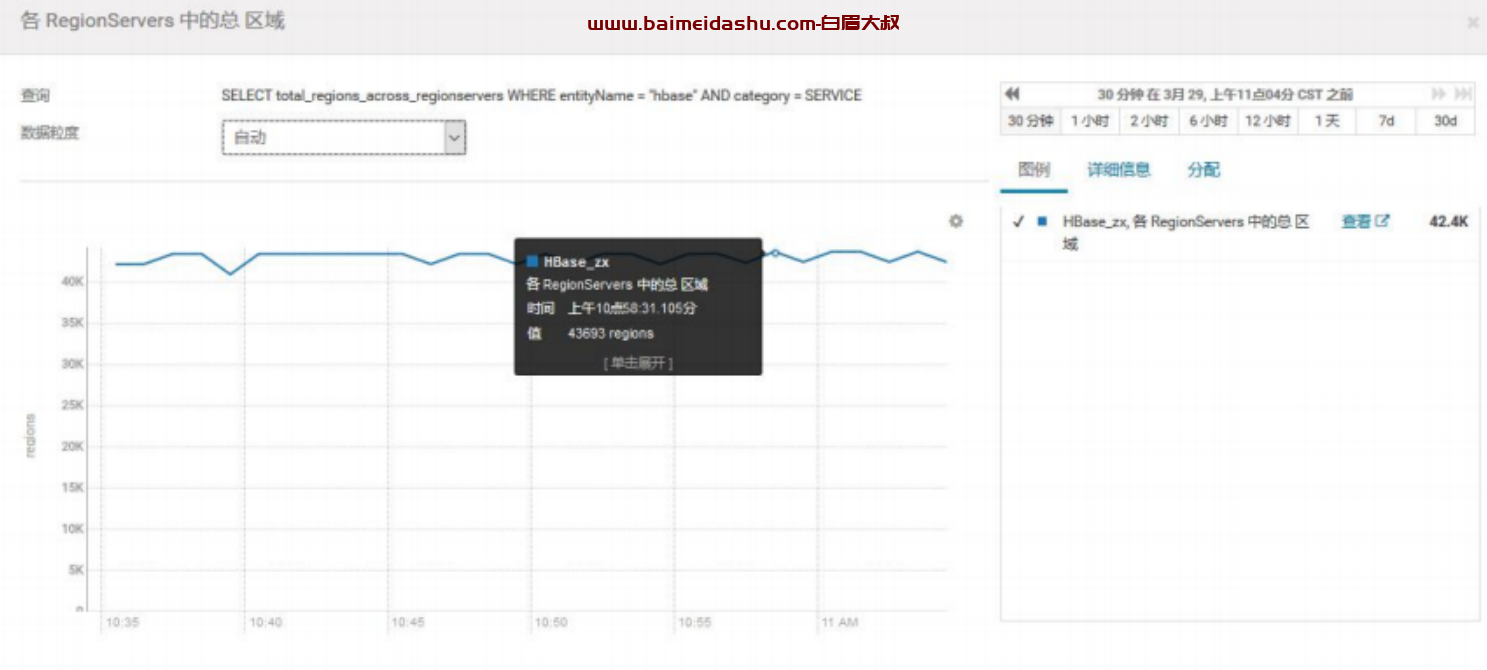
平均每个 RegionServer 有 1000+的 region,已经比较高了,有风险
4.Master 状态查看,GC 时候有点高
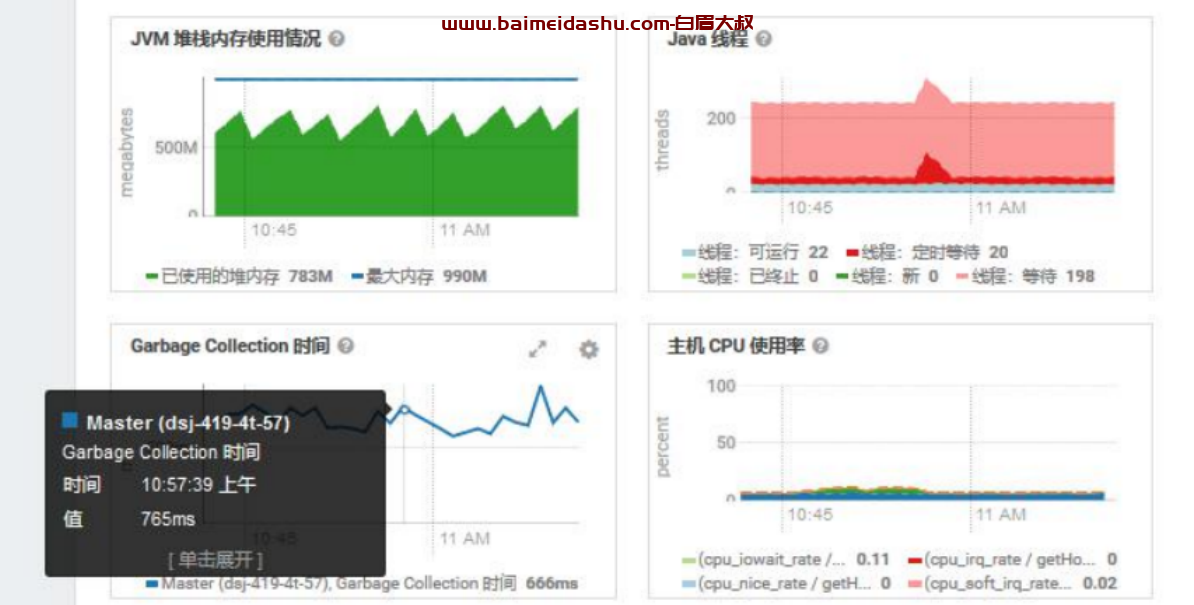
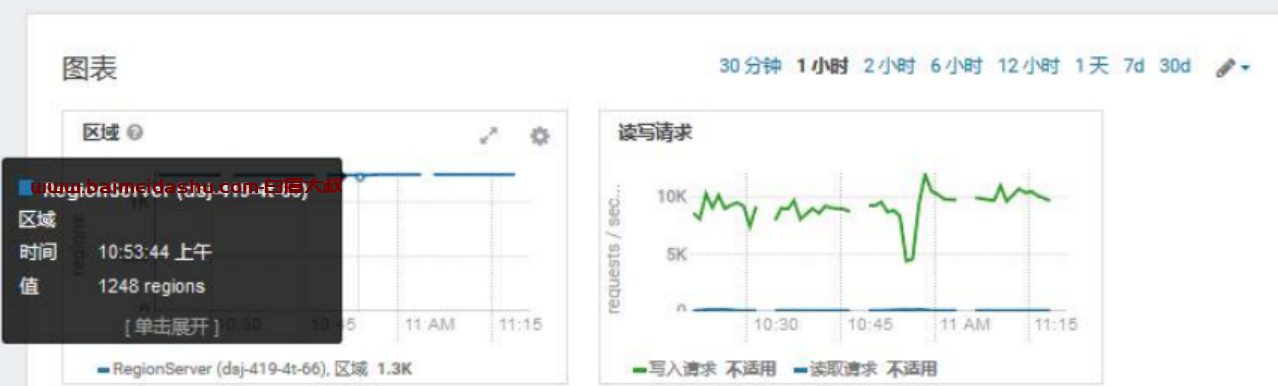
5.查看单个 RegionServer 情况
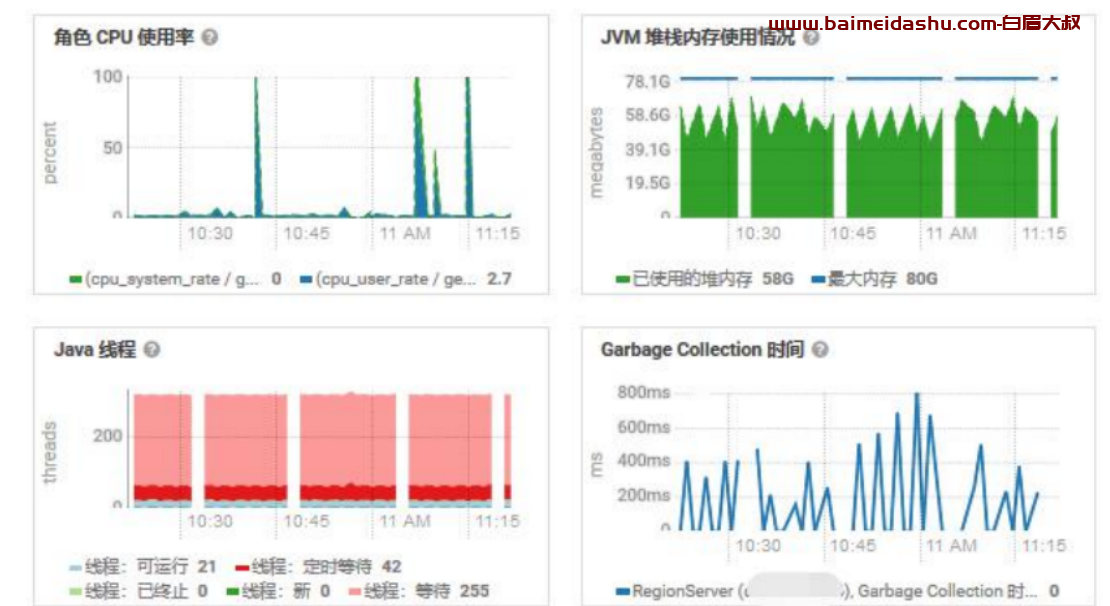
2.查看备用 HMaster
每个库正常来说都有 3 个主节点,一个正在跑,两个备用,如图所示。
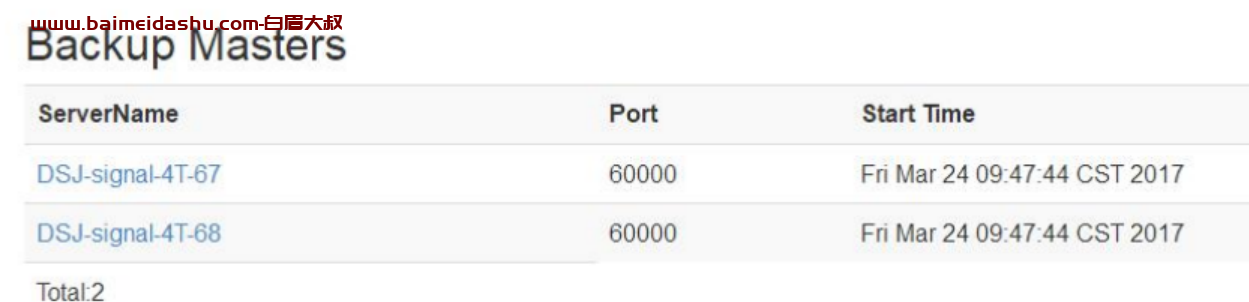
3.查看 Requests Per Second 和 Num. Regions
若为图中所示为 0,则需要登录主机查看,通常这种情况会发生在重启节点主机后发生
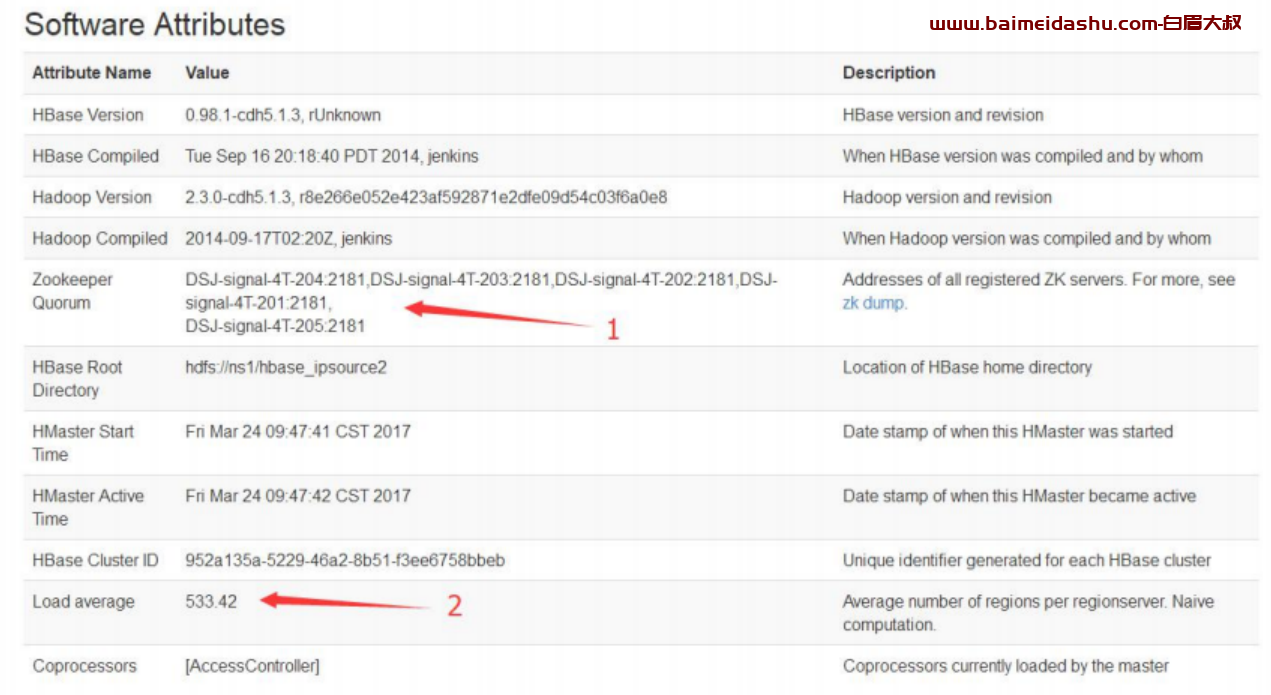
4.查看 Software Attributes
图中所示,比较重要的是两个标出部分:
1:代表着本库的 zookeeper 节点,如果出现异常,总数会不正常的
2:代表着本库的平均 region 数,理论超过 300 就要进行合并操作的,但这个是根据业务的需求进行操作,业务侧提出数据库卡顿了,再进行合并操作即可
5.查看 Dead Region ServeRegionServer
登录 HBase UI,若有 HBaseregionserver 宕掉的节点,则页面上会显示
出如下情况:

出现这种情况,则说明有非正常节点,可以尝试登陆该故障节点,查看故障原因(如 HBase 进程消失,主机意外重启,主机死机等)
欢迎来撩 : 汇总all

