
集群作业执行缓慢问题排查 1
问题发现
2022-05-07 XXX 告知 XXX 集群作业跑的很慢,提供作业 ID 为:application_1523379785773_87898
问题排查
作业查看
排查的时候作业已经执行完毕,发现只有 58 个 map,且没有 reduce,实在不应该慢!
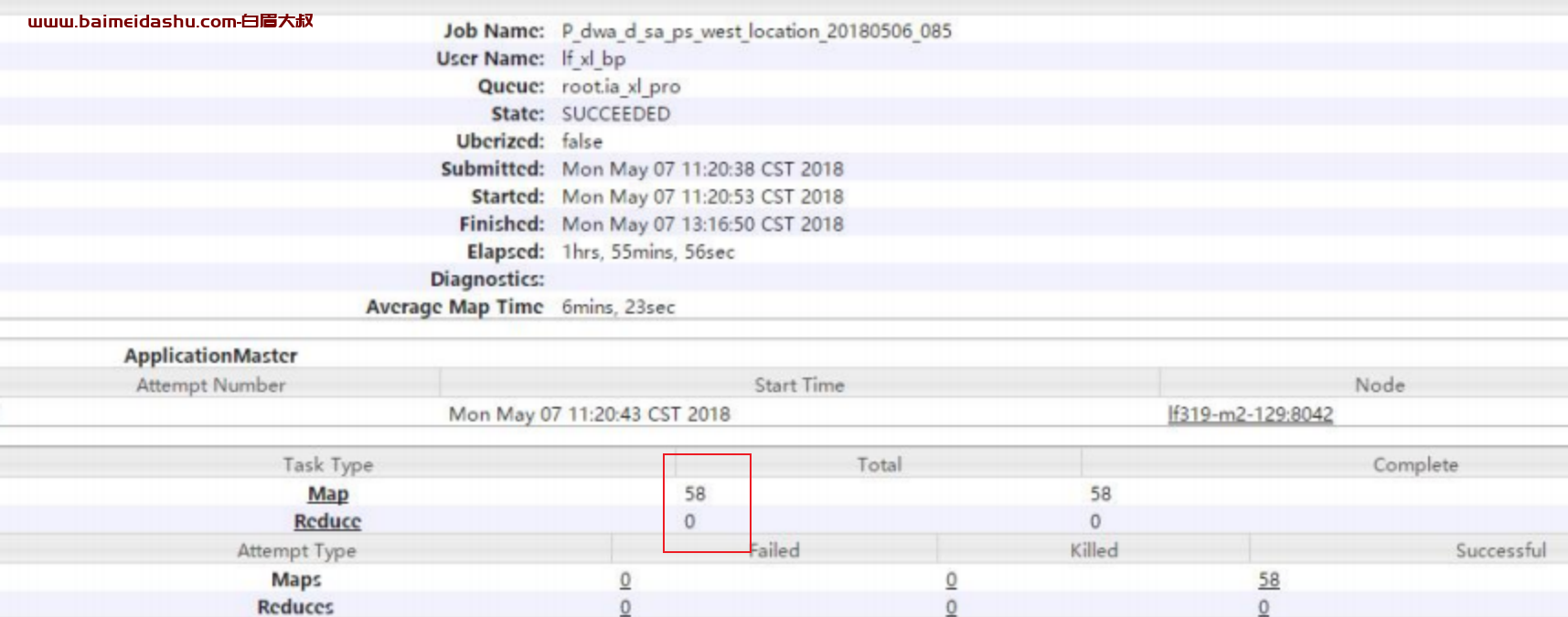
查看 map 执行情况,发现其他机器上的 map 执行很快,唯独这个 map 执行巨慢!,故此推断不是 job 的问题,而是机器问题。
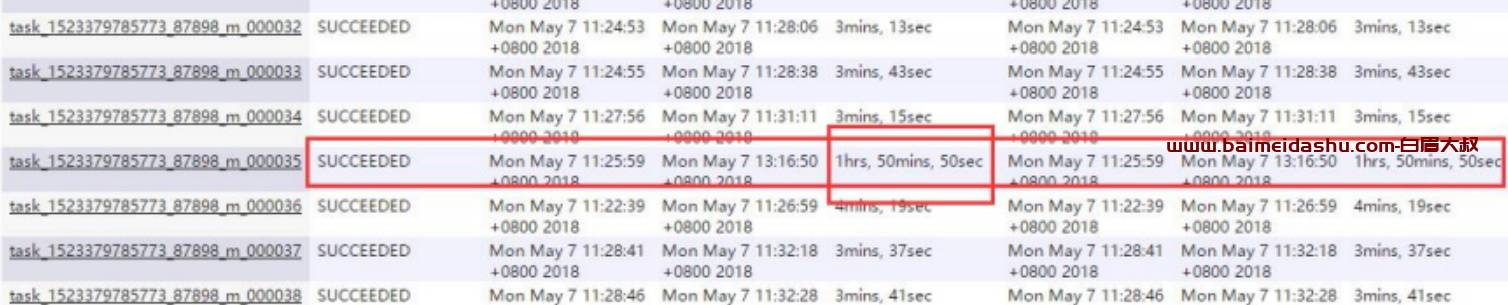
此 map 是运行在 lfxxx-m2-132 机器上。
查看该 map 的 counter,发现
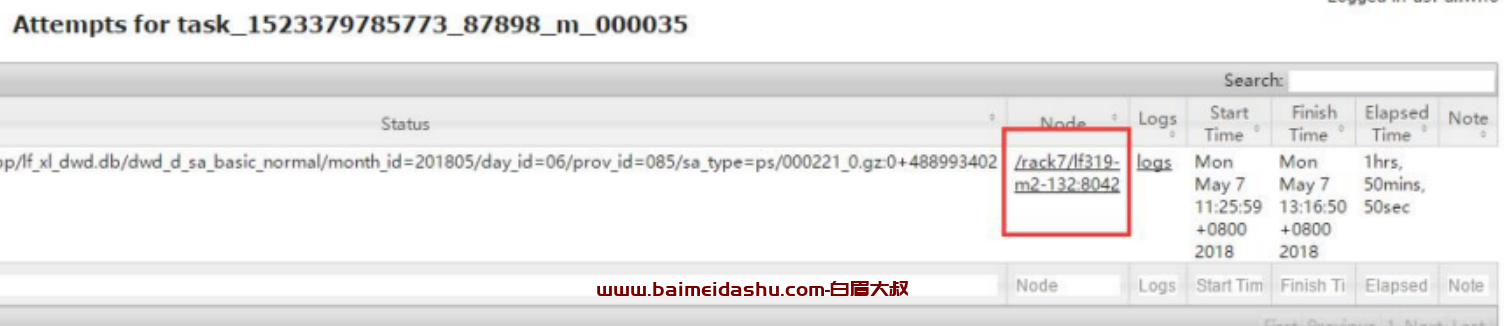
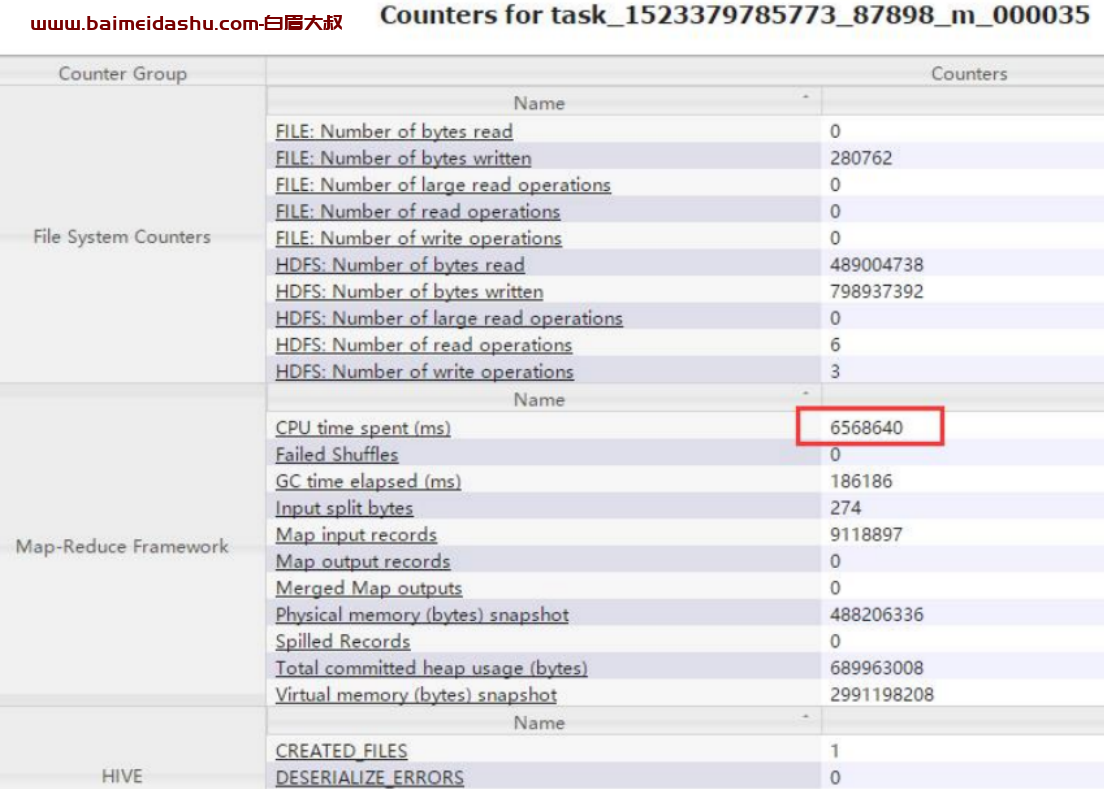
cpu 消耗时长很大,大概 100 分钟
查看资源队列,发现很闲!

查看主机列表
原来只有 132 负载高,现在出现了其他负载高的机器,不过经过观察其他机器的负载不会一直高,但是 132 的负载一直高,所以暂时只看 132 机器
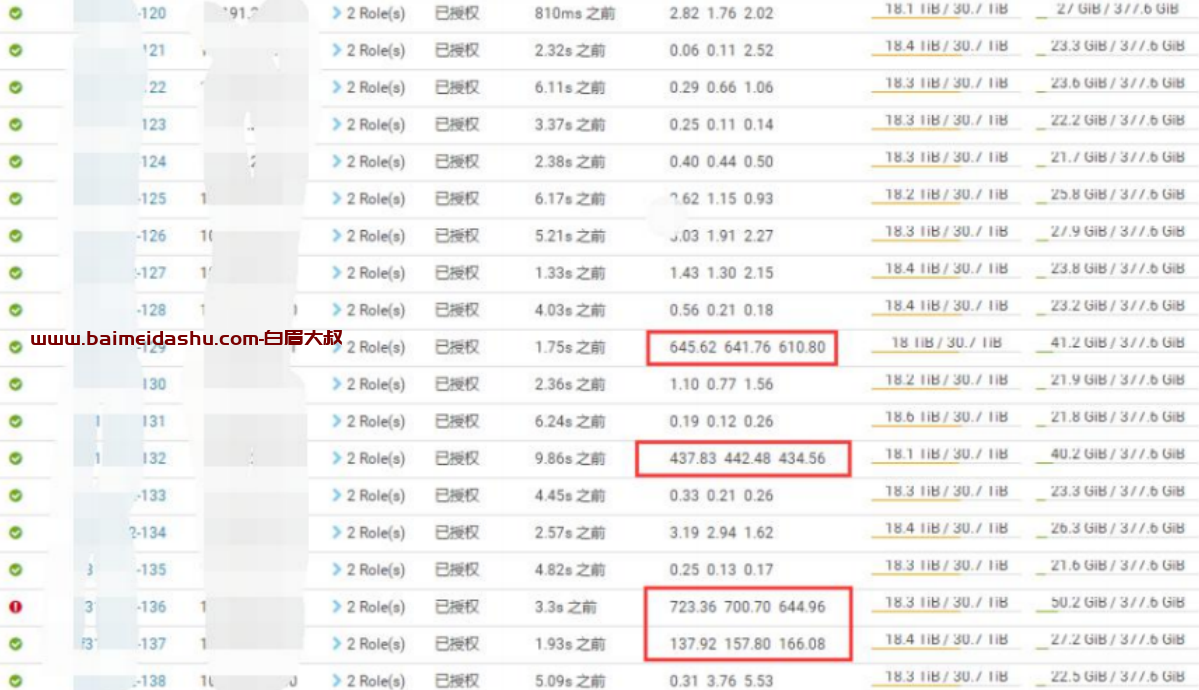
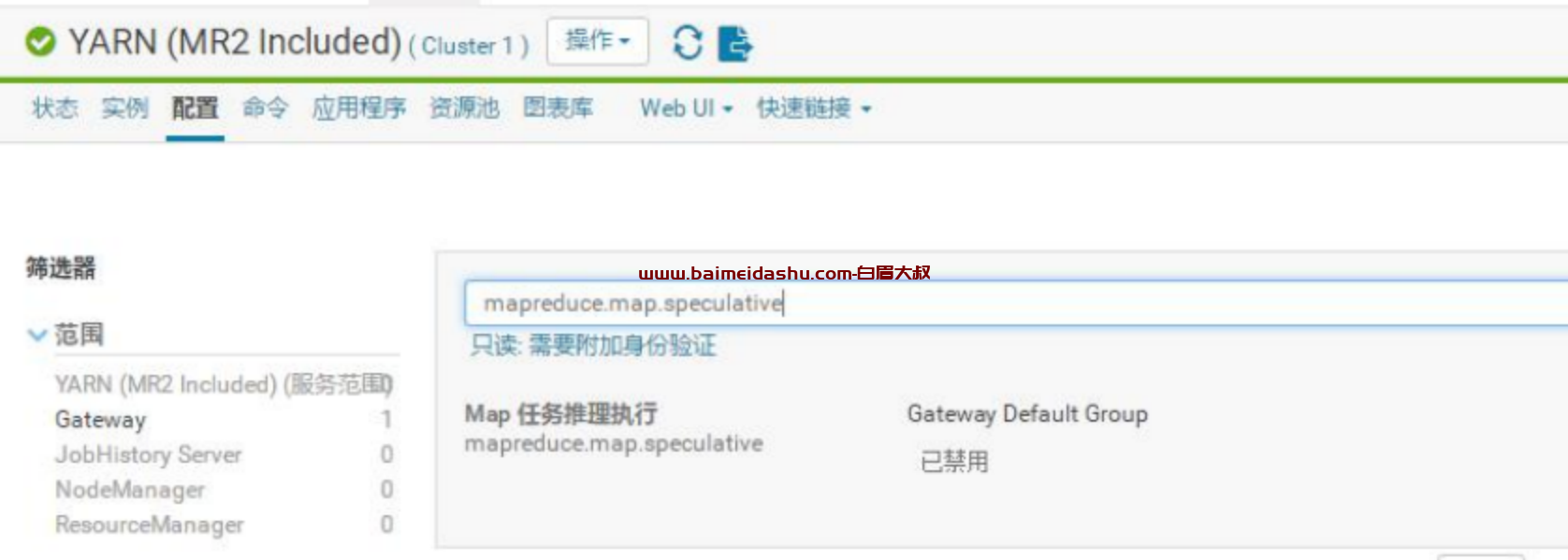
看了下 mapreduce 推测执行的参数,发现是禁用,所以 map、reduce 的任务一旦卡死就会卡很久,目前咱们的集群资源不紧张,可以考虑开启此参数。
查看 132 服务器状态
cpu 使用率基本是 100%
发现最近两三天 lfxxx-m2-132 负载急剧上升
进入 132 服务器系统后发现负载确实很高
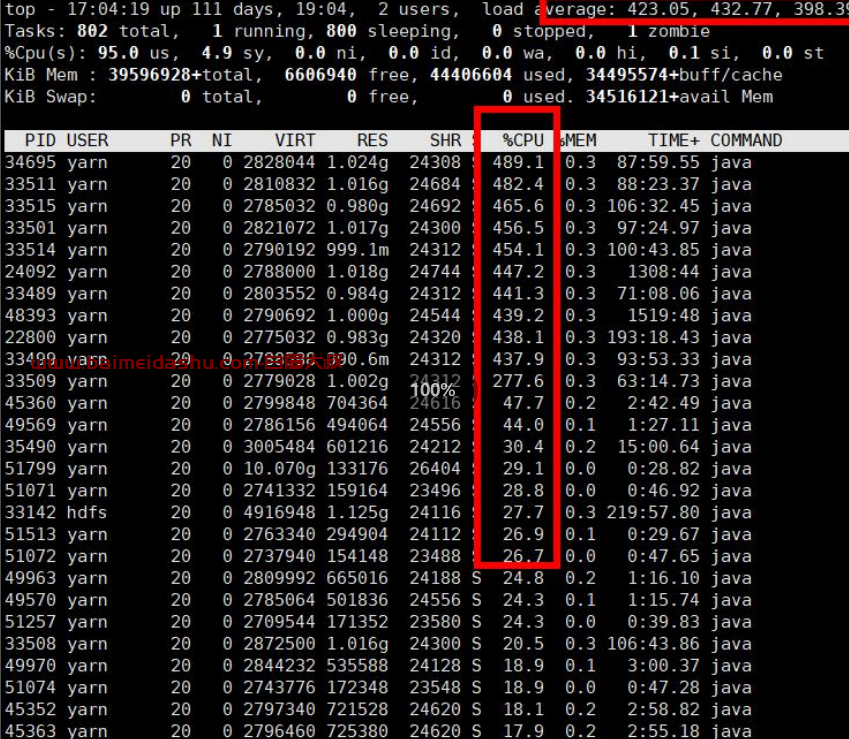
内存使用很少:

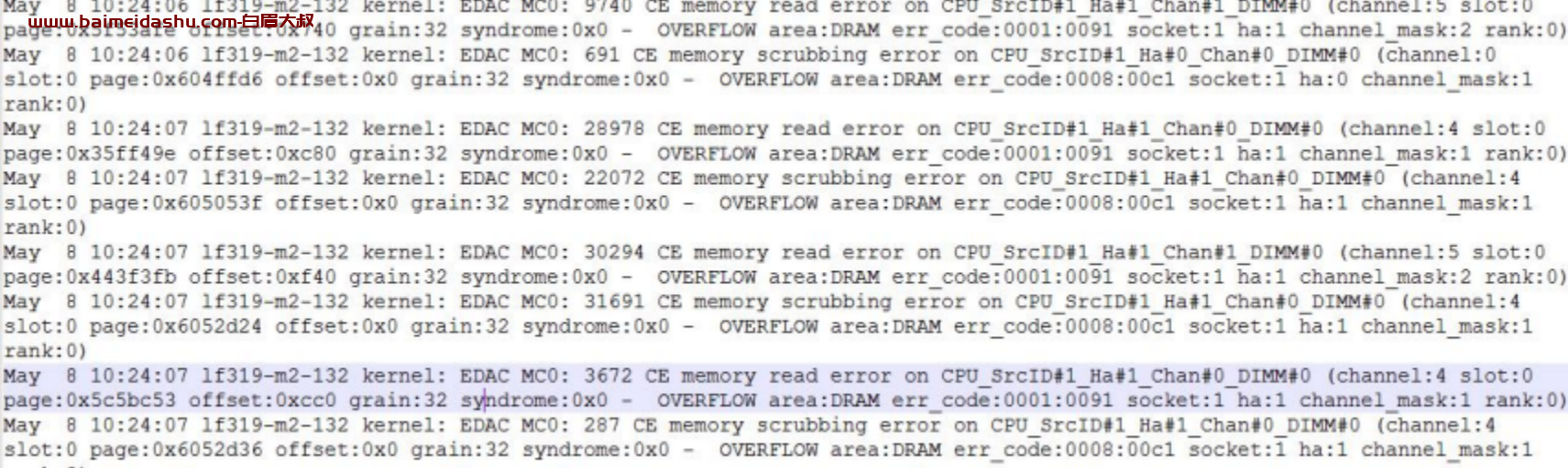
查看 132 状态系统日志
发现大量如下日志:
还发现如下问题:
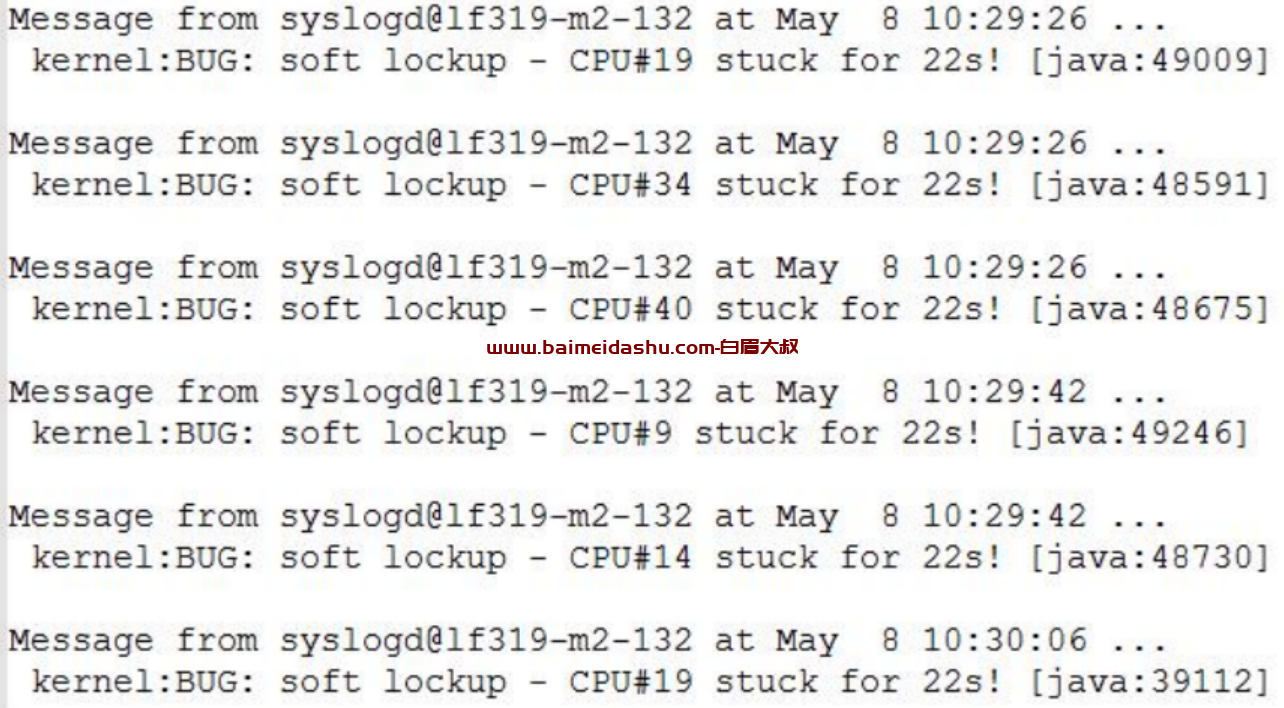
lockup 的概念:
lockup 分为 soft lockup 和 hard lockup。 soft lockup 是指内核中有 BUG导致在内核模式下一直循环的时间超过 10s(根据实现和配置有所不同),而其他进程得不到运行的机会。
解决
将日志提供给 IAAS 负责人,IAAS 负责人联系了厂家,厂家判断内存故障,第二天更换内存。
同时主机侧发现 132 机器卡死,重启了服务器,重启后错误日志不再打印,机器负载恢复正常。
可能是两个问题:
1、触发了内核 bug,导致 cpu 使用率过高,任务很难得到CPU 的资源。
2、内存可能也确实存在问题
集群资源很充足,是否考虑开启推测执行,这样即便有个别机器故障也不会对作业执行时间影响太大。
欢迎来撩 : 汇总all

