
NameNode RPC 负载过高
一、问题发现
2019-10-18 基于小文件问题与 XXX 和 XXX 了解多租户初筛程序问题,发现初筛程序URLFilter_Hour_Tenants 在执行之前会获取文件信息,获取文件信息需要 2 至 5 小时才能完成
问题排查
业务情况:
目前处理 HHH 日志的程序有如下:
YX:凌晨 1 点分省处理昨天一天的数据2、HHH 日志初筛,按小时处理省份数据,rpc 请求为 31 万,缺点:每小时每个省份的作业处理却要扫描当天此省份全量文件信息,造成大量无用的 rpc请求
3、Spark streaming 实时采集原始日志,目前是增量获取文件信息,对 rpc的压力影响较小
HHH 日志初筛现象:
Job 输入目录有 31 万的文件,这个任务读取整个文件夹其中的 1.4 万的文件。如下截图是初筛 job 的 rpc 请求,请求次数为 310172,从日志上看每秒钟并发十几次到几十次,耗时 3 个半小时,并发度太低的原因是因为 rpc 请求队列堆积了很多请求
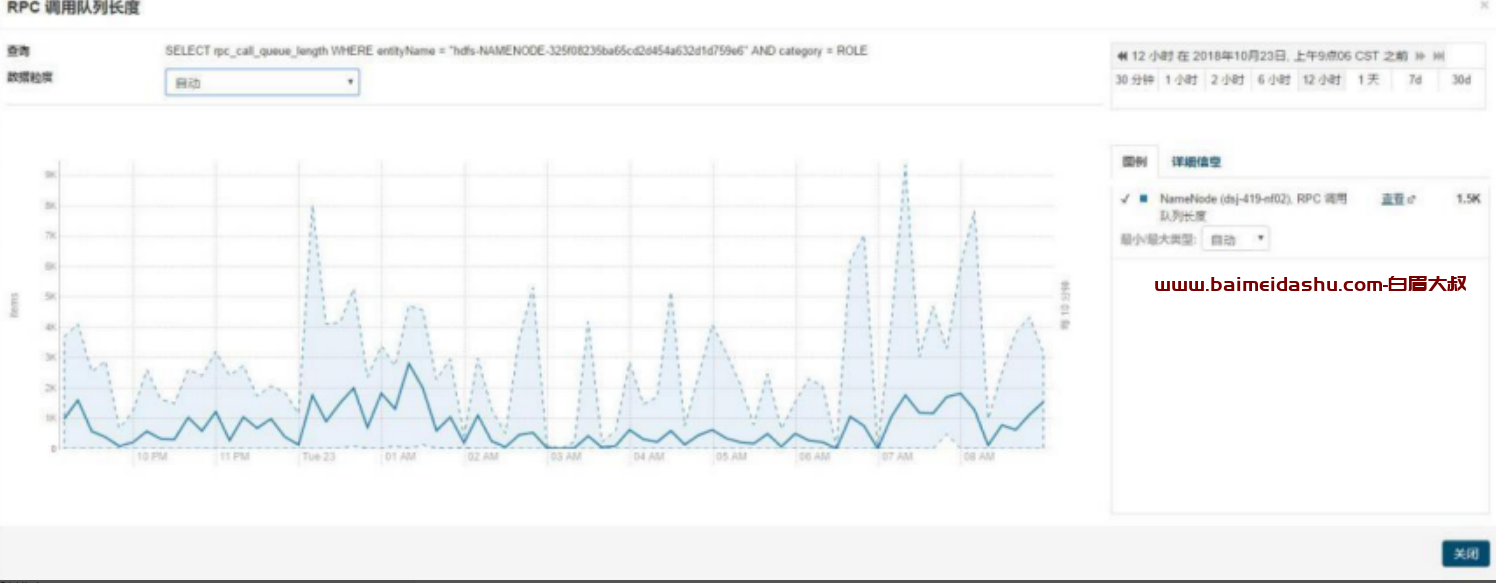
rpc 监控
昨天晚上 23 点到今天凌晨 2 点的时候,rpc 队列累积请求长度较高
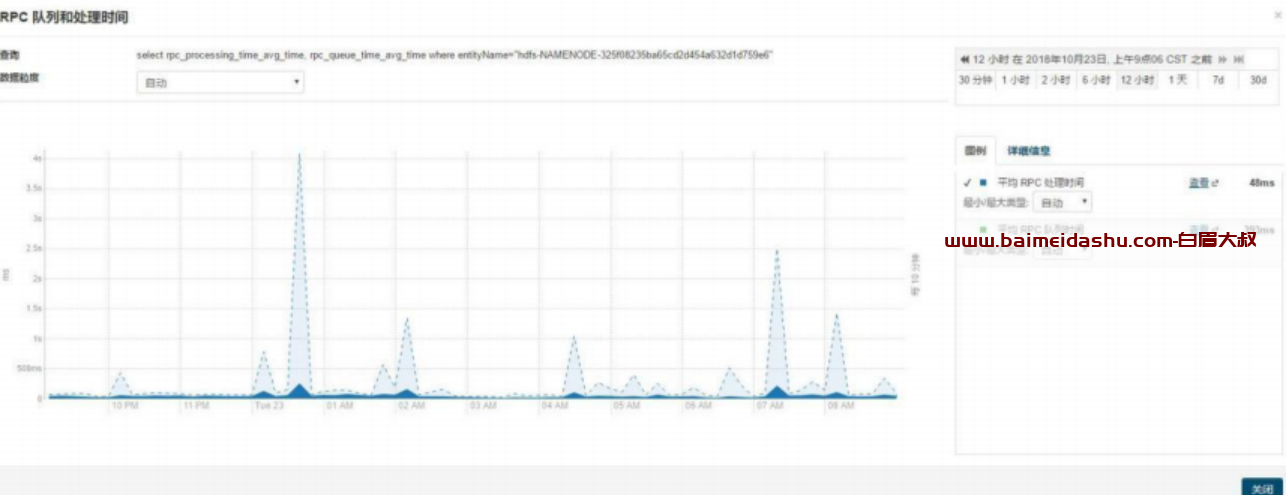
昨天晚上 23 点到今天凌晨 2 点的时候,rpc 平均请求时长偏高
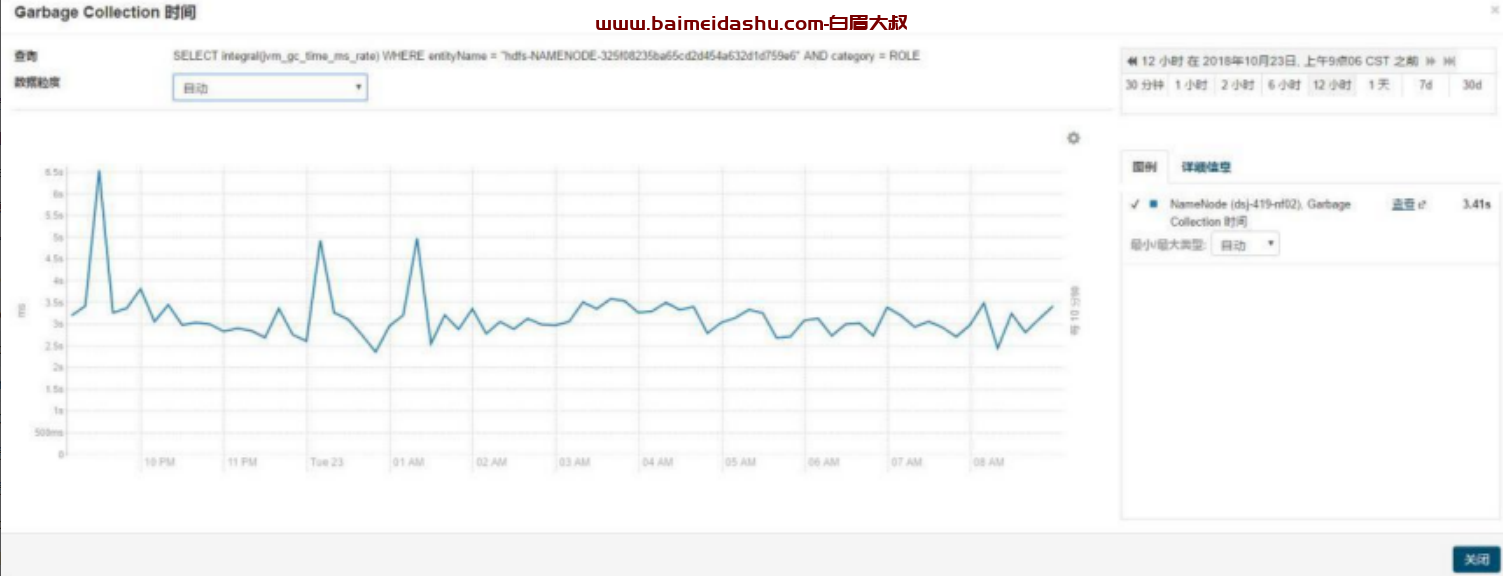
解决方案
1、HHH 多租户初筛程序由原来的 MR 批处理改为 spark streaming 实时采集处理,降低 rpc 负载,XXX 协助 XXX、XXX、XXX 改造程序
2、spark streaming 数据直接输出到租户对应目录,省去 mv 环节
3、预计两周上线,上线前需做代码、流程评审
欢迎来撩 : 汇总all

