
spark 丢失临时文件问题
HHH 日志改造问题
背景
目前 HHH 日志初筛程序由于 RPC 处理时间过长,需要优化改造成 SparkStreaming 处理;
同时,HHH 日志解析后续 DP、DK、DEL 表生成同样适用MR 处理,浪费大量资源,可改造合并到 Spark Streaming 中一块处理。但在合并初筛、HHH 日志解析、DP、DK、DEL 时,碰到一些问题,请大家帮忙解
决一下。
Spark 版本:2.1.3
问题描述
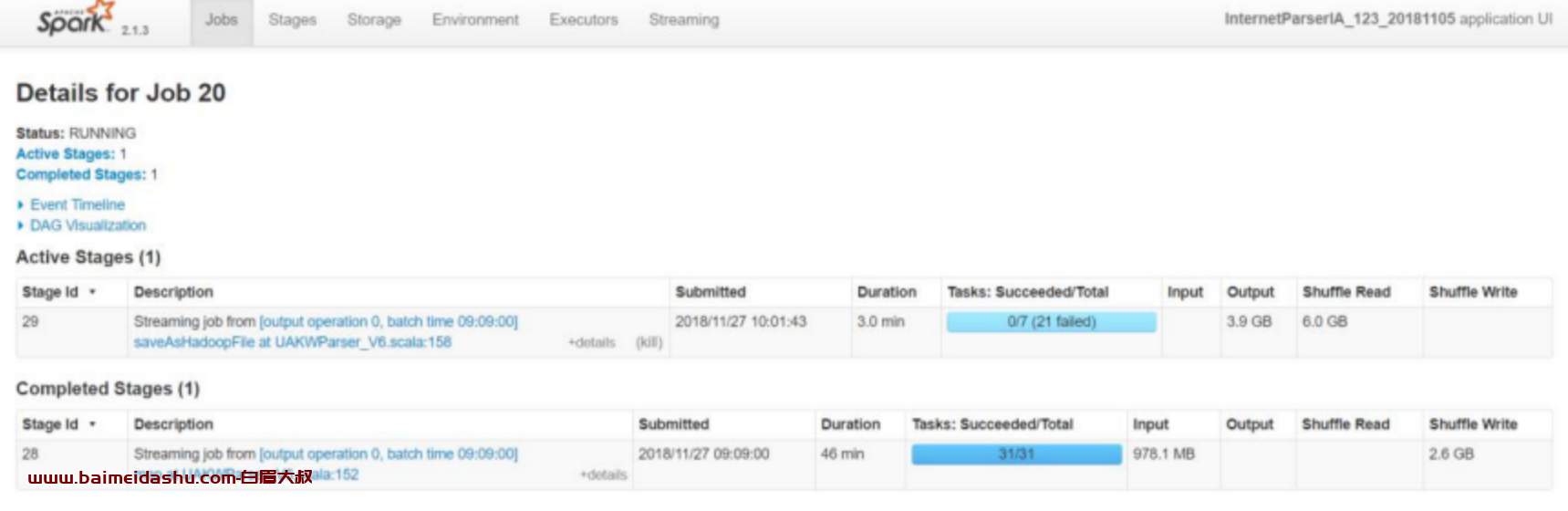
Spark Streaming 处理时,落盘到 HDFS 时,会报错找不到临时文件,具体如
下截图:

尝试解决方法
更改 xceiverCount 值
参考链接:https://blog.csdn.net/xiaolang85/article/details/19683815在测试集群中增大 xceiverCount 值为 65536.更改后还是会报同样的错。
更改 repartition 为 partitionBy
更改如下图:

使用 partitionBy 代替 repartition,减少同时操作文件数
实验结果:还是会报同样错
取消 repartition、partitionBy
去除 repartition 和 partitionBy,发现落盘时会报同样错。
猜测 batch 过大,增大 executer 内存 和 设置 peRegionServerist 级别为
MEMORY_AND_DISK_SER
没有解决
取消多目录输出 saveAsHadoopFile
为方便后续处理文件,本次改造时,按不同目录对初筛、DP、DK、DEL 文件
输出。更改 saveAsHadoopFile 为
saveAsNewAPIHadoopFile[TextOutputFormat[String,String]](outPath)
发现落盘时会报同样错
麻烦大家看一下这个问题,找出解决方法。
问题原因确认
问题原因
由于 spark 代码中设置了 spark.streaming.concurrentJobs 参数,该参数的作用为 spark 多时间窗口 job 并发执行数量,启用改参数后,在相同输出目录下,多个 job 的临时目录是一样的,在其中一个 job 执行完成后,会删除临时目录,其他执行中的 job 则找不到该临时目录,导致报错
解决方式
根据时间窗当前时间,设置时间戳子目录,使每个时间窗 job 拥有自己的独立目录,保证多个 job 的临时目录是独自使用的
注意:子目录必须在输出数据前设置好,不能在自定义的分目录输出中设置
欢迎来撩 : 汇总all

