
多个 datanode 节点存储不足案例
1.案例
2019 年 4 月 26 日下午,yz-4m1-02 集群的多个 datanode 可用空间不足,并引发 CM 页面告警。
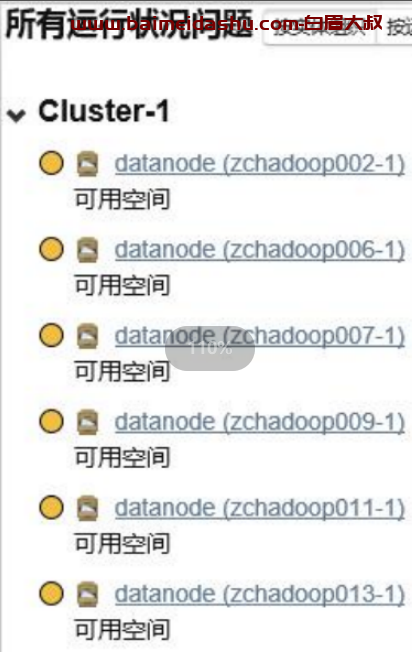
HDFS 页面显示所有 datanode 存储的标准差已达 11%(正常情况下是 5%)
![]()
2.解决方案
运行 Hadoop 自带的 balancer 程序,平衡 HDFS 中的各节点间的差距。在任意节点都可以启动 balancer,但是建议选择空闲(内存占用低)的节点。
3.执行 balancer
①在内存占用较低的 zchadoop002-1 上启动 balancer 脚本,将 HDFS 中所有节点的存储值中的最低值和平均值的差值设置为 5。
命令:start-balancer.sh -threshold 5

启动 balancer 后,在屏幕输出了 balancer 的日志路径
②设置 balancer 所能占用的带宽
带宽的大小与负载均衡的速度成正比,但是速度过大可能会导致map/reduce 运行缓慢,所以务必选择业务空闲时间段启动 balancer。默认的带宽为 1048576(1M/S)。由于 balancer 可以在中断后重新执行(类似于迅雷的断点续传),所以可以先设置一个较低的带宽,慢了的话,再一次次加速。
此处设置为 2M/S。需要强调的是,balancer 每次设置的带宽是临时性的,第二次启动 balancer 时,要重新设置带宽。
命令:hdfs dfsadmin -setBalancerBandwidth 2000000
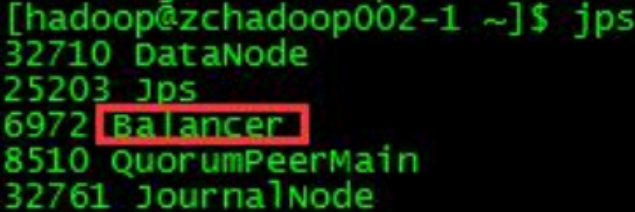
③查看进程
balancer 是一个 java 程序,可 jps 查看。
④查看 Balancer 的进展
除了通过 HDFS 页面中的存储变化来间接反映 balancer 的进展外,还可以通过日志来量化其进展。
命令:more /opt/boh-2.0.0/logs/hadoop/hadoop-hadoop-balancer-zchadoop002- 1.out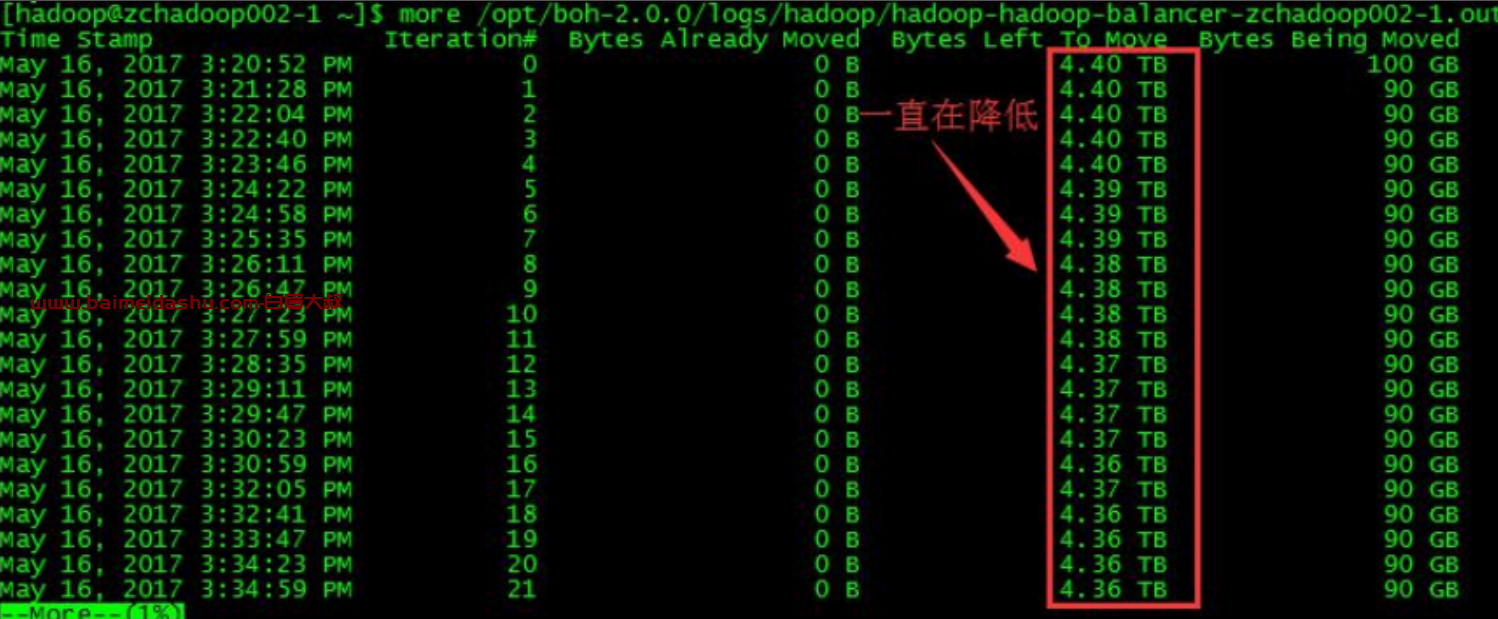
可以看到每次迁移中的待迁移数据 Bytes Left To Move 都在减少,说明balancer 在起作用。但为什么已完成的迁移量 Bytes Already Moved 一直是0 字节,还没搞清楚。
4.定时执行 balancer
因为 balancer 的速度由多方因素影响,我们不能保证当天的 balancer 在当天就能完成。又考虑到 balancer 有类似迅雷的“断点续传”特点,而且带宽在 balancer 中断后会失效,所以在每天的定时计划中的顺序是“停止昨天的 balancer→设置带宽(非必须)→启动今天的 balancer”。balancer 的运行时间段应当避开主机繁忙期。
下图以 yz-4m1-01 集群的定时计划为例。

欢迎来撩 : 汇总all

