
datanode 数据盘坏盘故障
以 yz-4m1-01 机房 hadoop056 出现坏盘为例
1.发现故障
目前发现数据坏盘的方式有两种,通过监控系统自动报警和在 CM 页面里肉眼观察。
自动报警:待定。
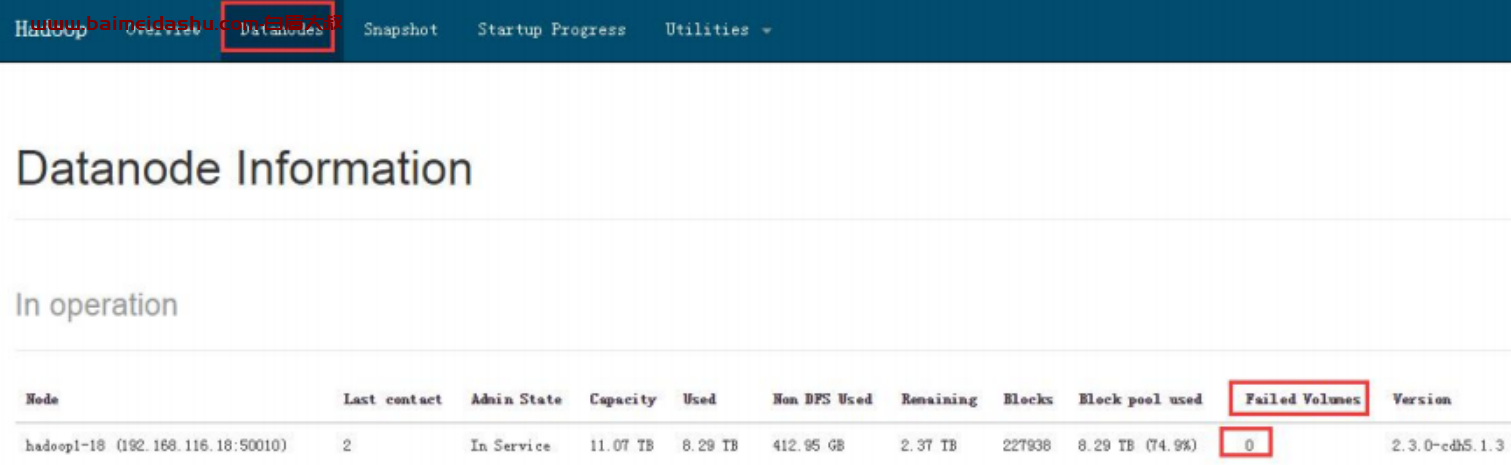
肉眼观察:在 HDFS 页面的 datanodes 目录 (http://132.35.xx.xx:50070/dfshealth.html#tab-datanode)里,观察 Failed Volumes 列的数值,若有非 0 值,则该值对应的 datanode 有坏盘。
2.停止 hadoop056 上的进程
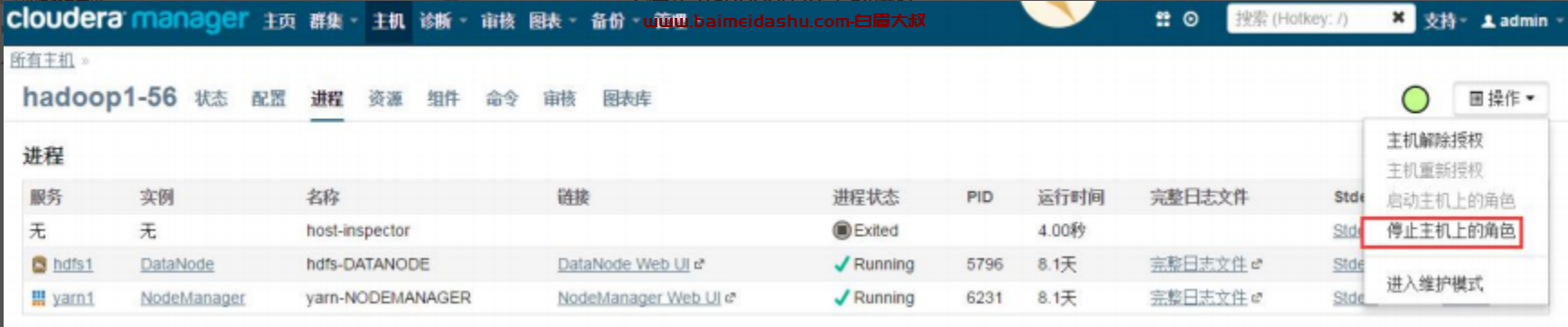
以 Admin 身份登录 CM,进入 hadoop1-56 的进程页面,在右上方的“操作”里选择“停止主机上的角色”
3.通知硬件侧更换硬盘
4.换盘后的操作
①以 root 身份登录到 hadoop056 节点
②停止 cloudera-scm-agent
命令:/opt/cm-5.1.3/etc/init.d/cloudera-scm-agent stop③返回 hadoop 用户,查看 datanode 进程是否已经停止
④切回 root,查看/data 目录,找到新换的盘。
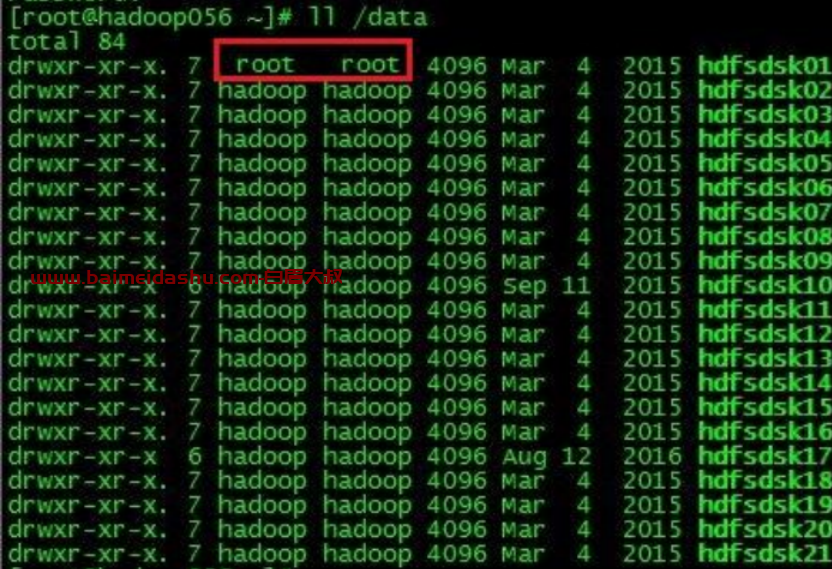
属主和属组是 root 的磁盘就是被更换的新盘。
⑤在新换的磁盘目录 hdfsdsk01 下新建目录
在正常情况下,以 hdfsdsk02 为例,磁盘目录里应该有如下 5 个目录。

但是新加的磁盘是没有红框里的 4 个目录,需要我们手工创建。
只创建第一级即可,它们下面的目录和文件会在 datanode 进程启动之后自动生成。
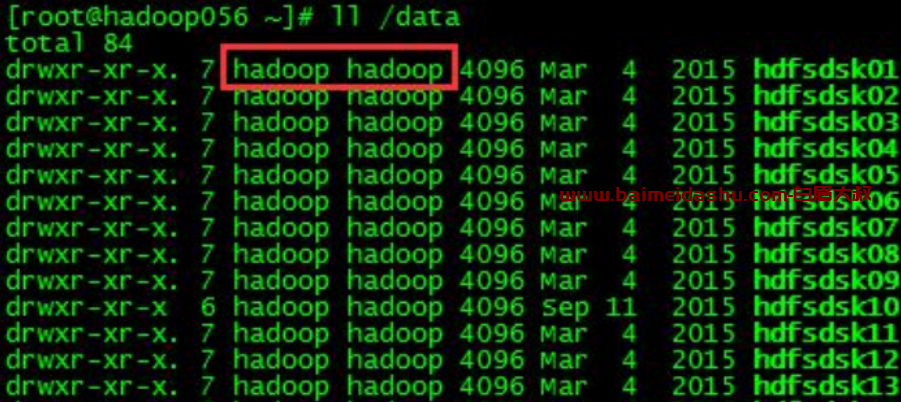
⑥修改新磁盘目录的属主和属组为 hadoop
命令:chown -R hadoop:hadoop /data/hdfsdsk01改变属组和属主之后的效果
⑦启动 cloudera-scm-agent
命令:/opt/cm-5.1.3/etc/init.d/cloudera-scm-agent start⑧返回 hadoop 用户,检查 datanode 进程是否已经启动
jps⑨二次确认
检查新换的盘是否还有坏卷
命令:
fsck -y /data/hdfsdsk01若还存在坏盘,则通知二线 xx 处理。
欢迎来撩 : 汇总all

