
datanode 失联排查(一)
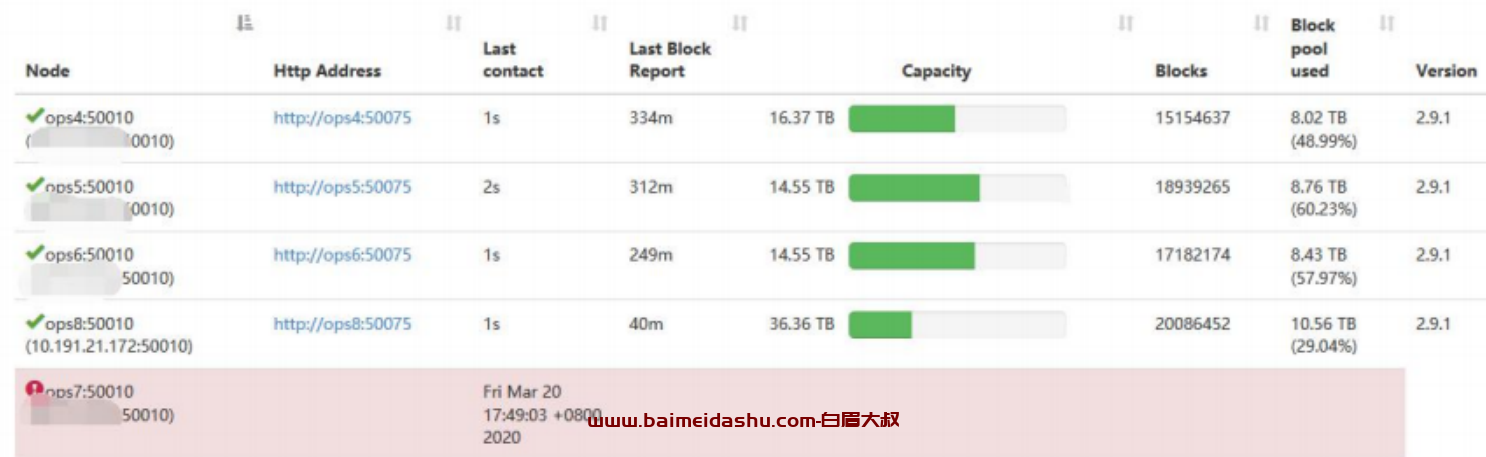
1.最近一段时间发现运维大数据集群 datanode 存在偶尔失联的情况,在重启datanode 和 namenode 时发现某几个 datanode 等待很长时间不联系namenode,导致失联,本次问题是在重启某个 datanode 时出现的问题,现象如下:
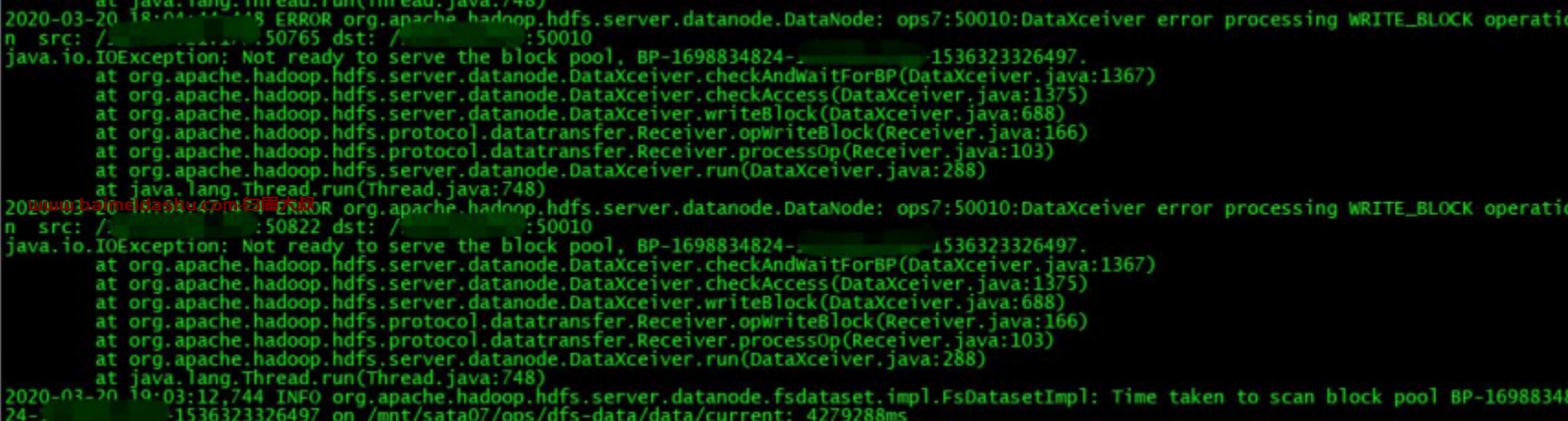
2.登录刚重启的 datanode 节点,查看日志发现如下错误,从错误上看 bolckpool 没有准备好去服务
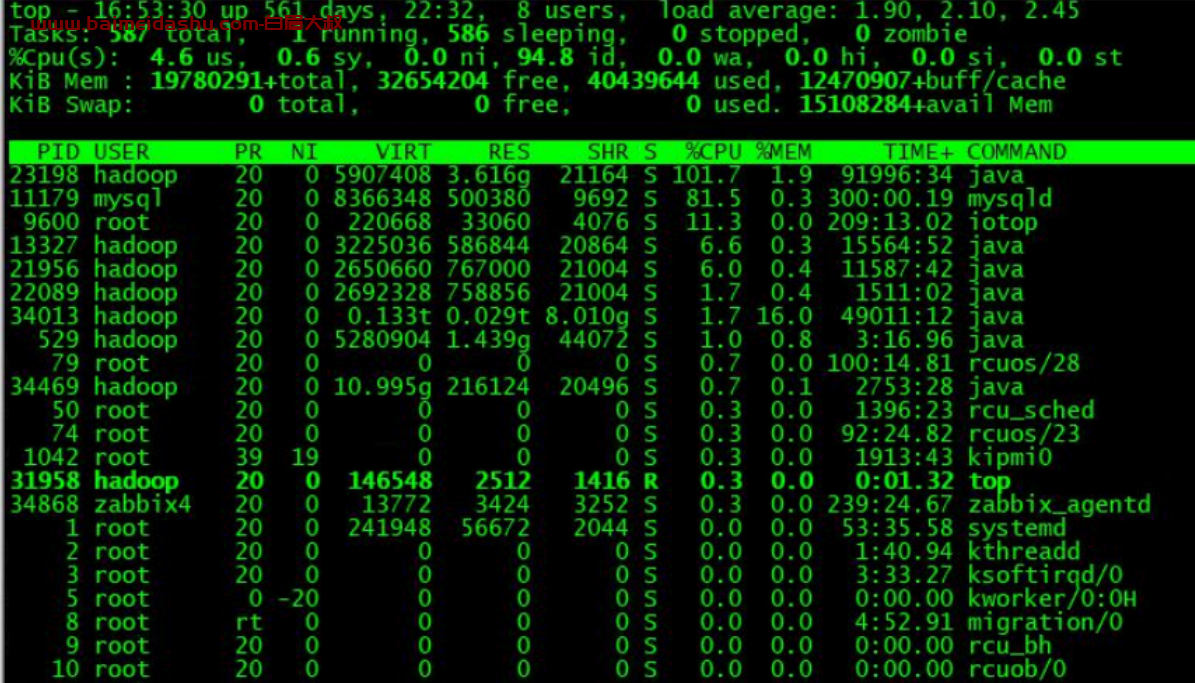
3.datanode 的问题一般会反应到 GC、系统负载、网络、IO查看 datanode GC,没有发现异常
jstat -gcutil 40338

查看系统负载也没有问题
查看网络流量,也没啥问题

查看磁盘 IO,发现明显有三块盘不正常,%util 过高,%util: 一秒中有百分之多少的时间用于 I/O,如果%util 接近 100%,说明产生的 I/O 请求太多,I/O 系统已经满负荷
iostat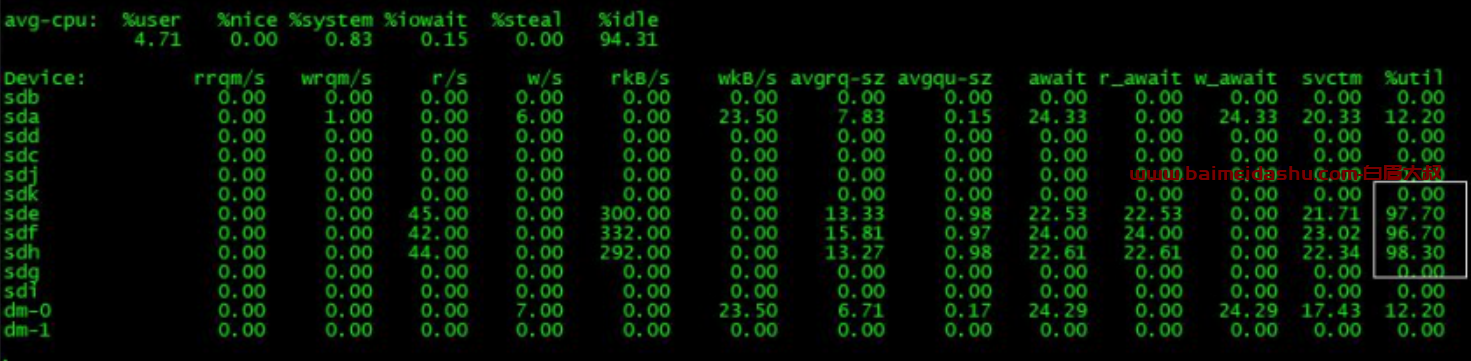
查看 iotop 发现有三个 du -sk 操作,是对 sata04、sata05、sata07 下的 blockpool 做操作,根据观察这 3 个 du 命令会持续很长时间
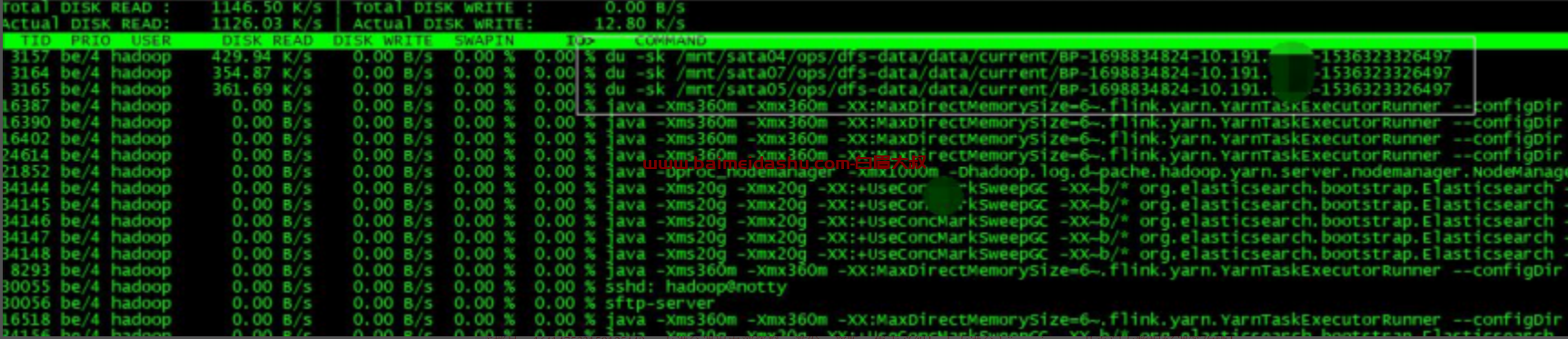
查看磁盘情况,发现 sata04、sata05、sata07 分别挂载在了 sde、sdf、sdh,正好与 iostat 中%util 过高的磁盘吻合
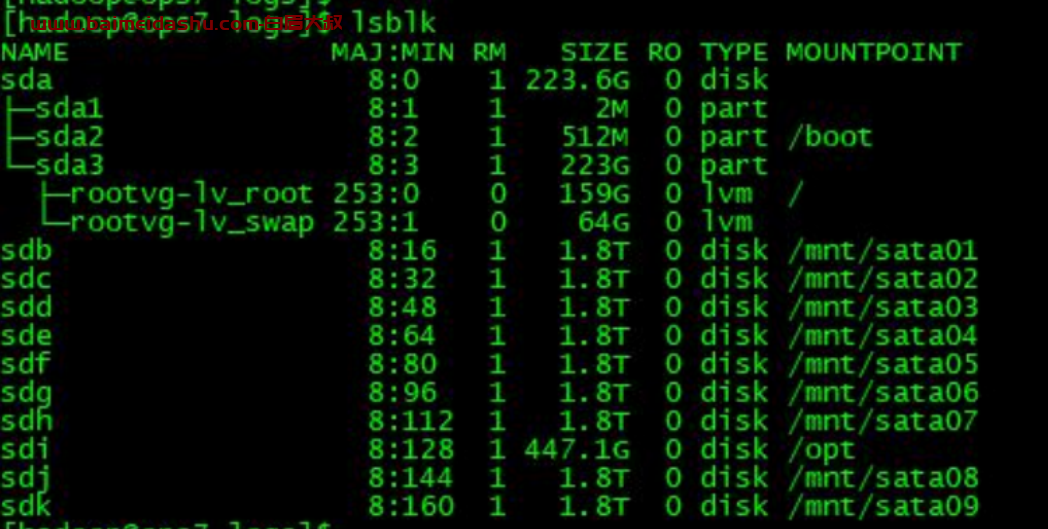
du -sk 是用来统计某个目录的大小的,根据 du -sk 显示的路径,是用来统计datanode 各个 Volume 的存储容量的,du 的运行机制是基于文件获取的,并非针对某个分区,执行时间受限于文件和目录个数,而从监控上看每个datanode 的纳管的 block 以及达到了 1500 万+
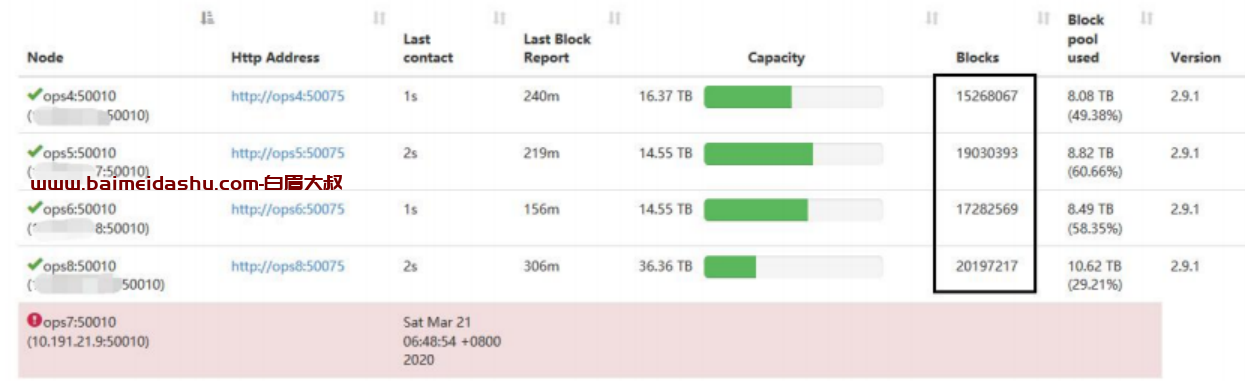
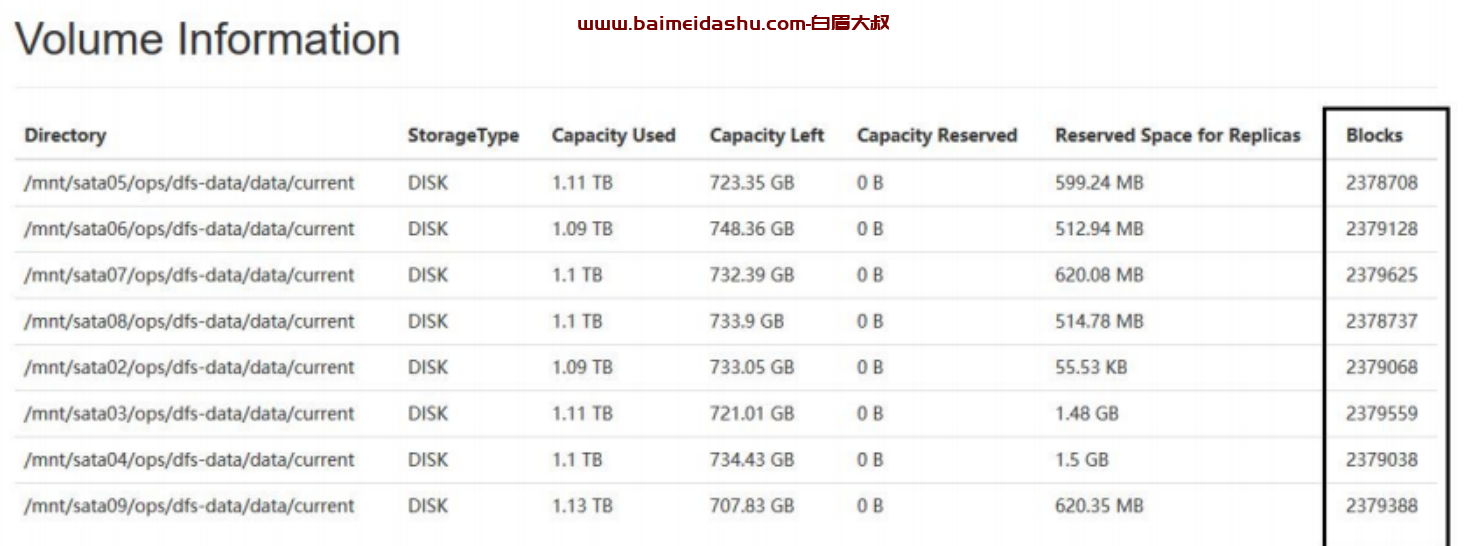
而单个 volume 存储的 block 数也达到了 230 万+,所以 du 会很慢,所以导致 datanode 一直启动不完成,导致失联
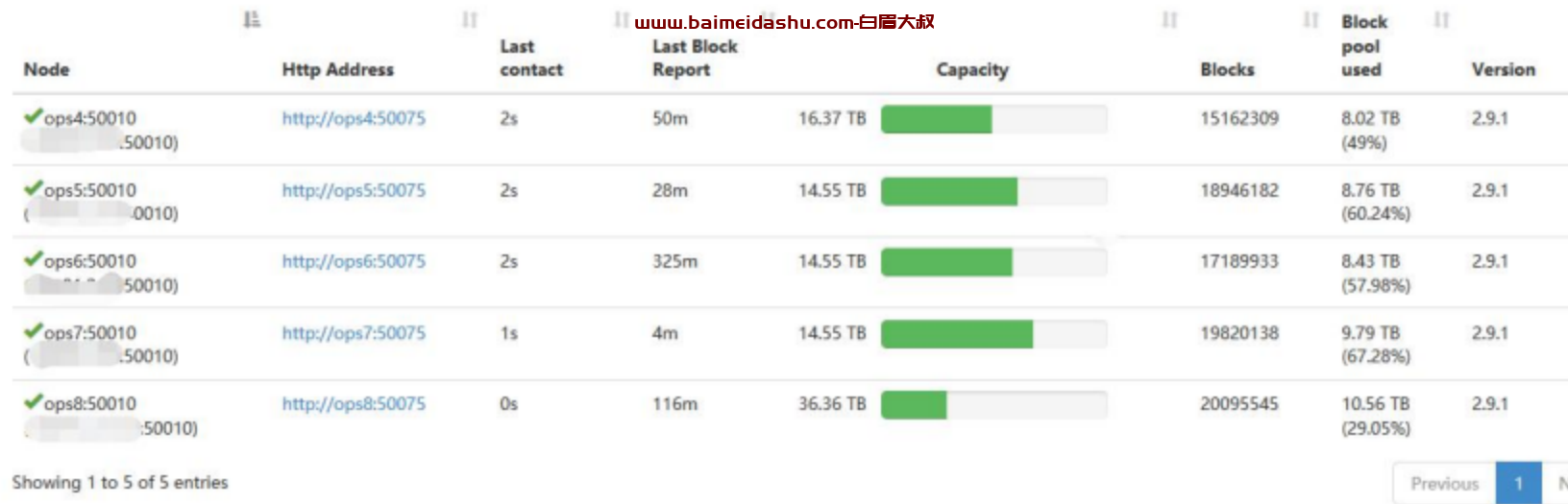
而我们的产线环境每个 datanode 纳管的 block 的数量才 20 万左右,运维大数据平台的 block 数整整比产线环境多了两个数量级
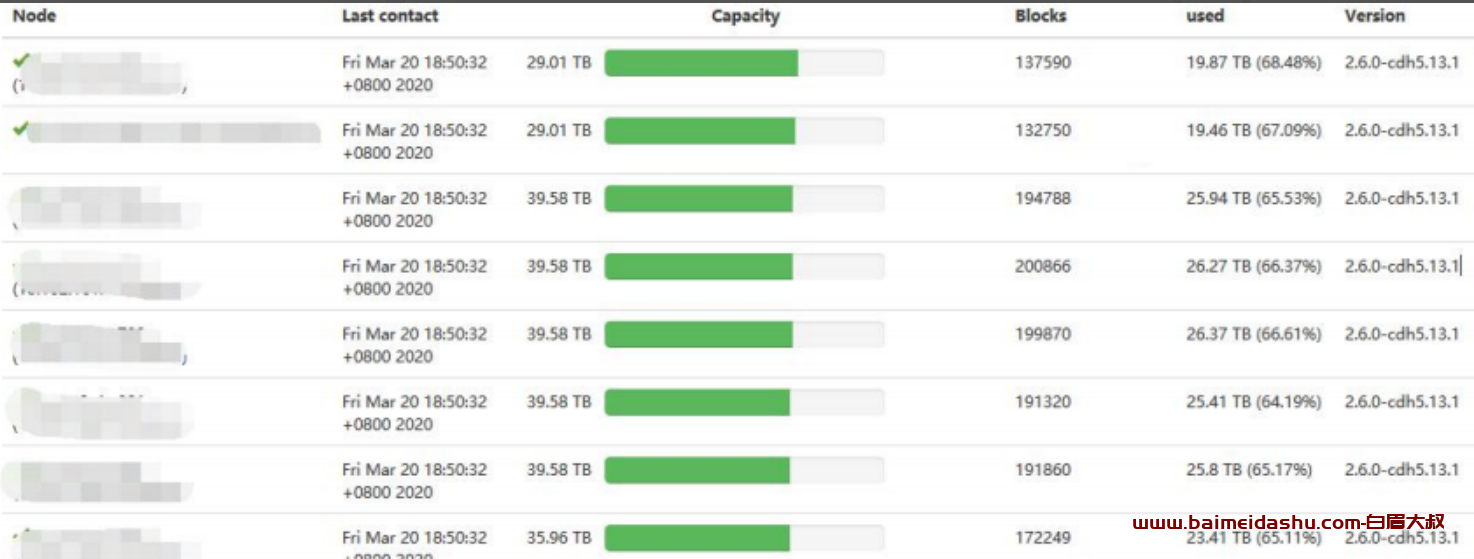
但是 datanode 总会恢复,大概需要 1.5 个小时
- 解决方案
https://issues.apache.org/jira/browse/HADOOP-9884
https://issues.apache.org/jira/browse/HDFS-14313
我的解决方案是使用 df 替换 du:
在 core-site.xml 里面增加配置:
fs.getspaceused.classname=org.apache.hadoop.fs.DFCachingGetSpaceUsed
df 直接使用 statfs 系统调用,直接读取分区的超级块信息获取分区使用情况,针对整个分区,直接读取超级块,运行速度不受文件目录个数影响,执行很快。du 和 df 不一致情况: 常见的 df 和 du 不一致情况就是文件删除的问题。当一个文件被删除后,在文件系统目录中已经不可见了,所以 du 就不会再统计它了。然而如果此时还有运行的进程持有这个已经被删除了的文件的句柄,那么这个文件就不会真正在磁盘中被删除, 分区超级块中的信息也就不会更改。这样 df 仍旧会统计这个被删除了的文件.
欢迎来撩 : 汇总all

