
生产环境中,Kafka 如何保证消息幂等性问题
1.Kafka 幂等性的必要性?
Producer 在生产发送消息时,难免会重复发送消息。Producer 进行 retry 时会产生重试机制,
发生消息重复发送。而引入幂等性后,重复发送只会生成一条有效的消息。Kafka 作为分布
式消息系统,它的使用场景常见与分布式系统中,比如消息推送系统、业务平台系统(如物
流平台、银行结算平台等)。以银行结算平台来说,业务方作为上游把数据上报到银行结算
平台,如果一份数据被计算、处理多次,那么产生的影响会很严重。
2.影响 Kafka 幂等性的因素有哪些?
在使用 Kafka 时,需要确保 Exactly-Once 语义。分布式系统中,一些不可控因素有很多,比
如网络、OOM、FullGC 等。在 Kafka Broker 确认 Ack 时,出现网络异常、FullGC、OOM 等
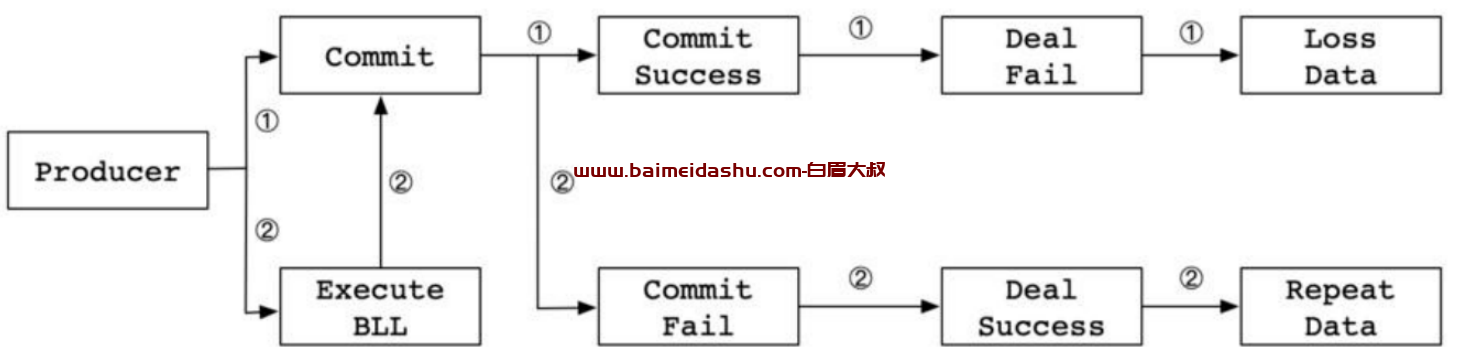
问题时导致 Ack 超时,Producer 会进行重复发送。可能出现的情况如下:
1)先 commit,再执行业务逻辑:提交成功,处理失败 。造成丢失
2)先执行业务逻辑,再 commit:提交失败,执行成功。造成重复执行
3)先执行业务逻辑,再 commit:提交成功,异步执行 fail。造成丢失
3.Kafka 的幂等性是如何实现的?
Kafka 为了实现幂等性,它在底层设计架构中引入了 ProducerID 和 SequenceNumber。
ProducerID:在每个新的 Producer 初始化时,会被分配一个唯一的 ProducerID,这个
ProducerID 对客户端使用者并不可见
SequenceNumber:对于每个 ProducerID,Producer 发送数据的每个 Topic 和 Partition 都对
应一个从 0 开始单调递增的 SequenceNumber 值。
4. 幂等性引入之前的问题?
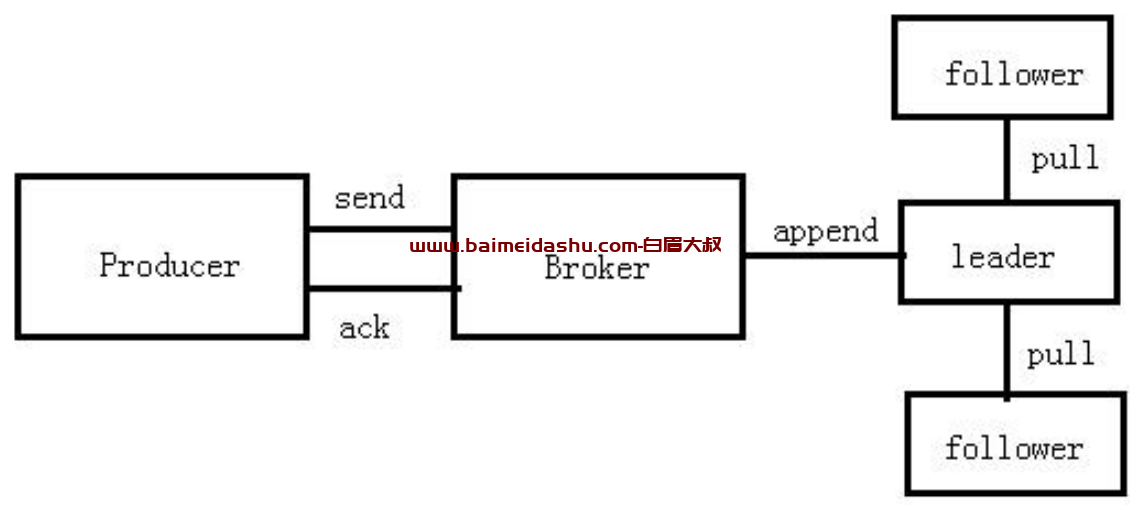
目前生产者发送消息(acks)有三种方式。
1)acks=0 (数据可能会丢失)
producer 不等待 broker 的 acks。发送的消息可能丢失,但永远不会重发。
2)acks=1(数据可能会丢失,也可能会重复)
leader 不等待其他 follower 同步完毕,leader 直接写 log,然后发送 acks 给 producer。这种
情况下会有数据重发现象,可靠性比 only once 好点,但是仍然会丢消息。例如 leader 挂了,
但是其他 replication 还没完成同步。
3)acks=all(数据可能会重复)
leader 等待所有 follower 同步完成才返回 acks。消息可靠不丢失(丢了会重发),没收到
ack 会重发。
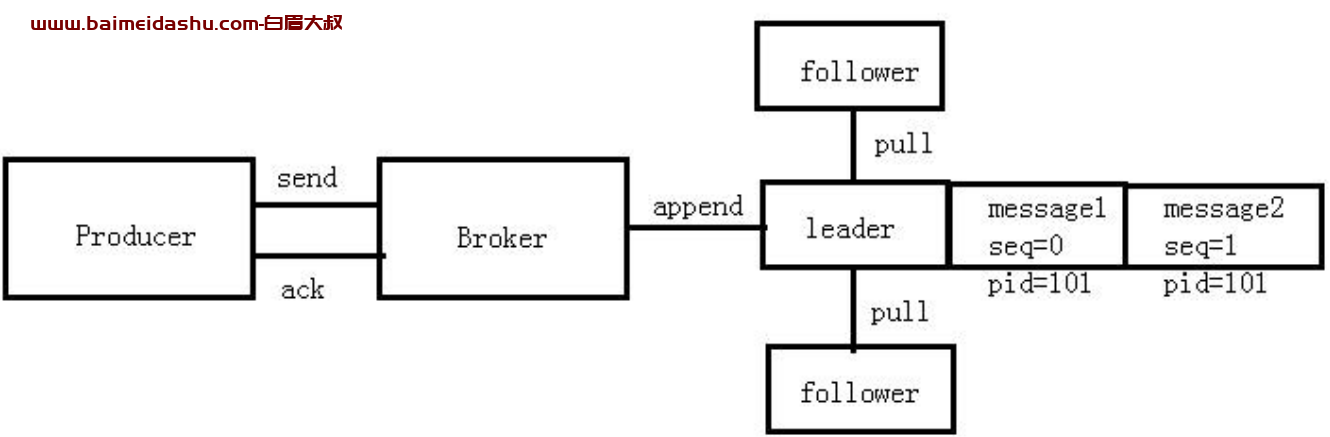
5.引入幂等性解决数据重发问题
当 producer 发送消息 message2 给 Broker 时,Broker 接受到消息并追加到 leader 中。数据
写成功后,Broker 返回 ACK 给 Producer,结果发生异常导致 Producer 接受 ACK 信号失败。
对于 Producer 来说,会触发重试机制,将消息 message2 再次发送,但是,由于引入了幂
等性,在每条消息中附带了 PID 和 Seq。相同的 PID 和 Seq 发送给 Broker,而之前 Broker
缓存过之前发送的相同的消息,那么在消息流中的消息就只有一条 message2,不会出现重
复发送的情况
6. Producer 幂等性使用
生产者要使用幂等性很简单,只需要增加以下配置即可:
enable.idempotence=true
7.Kafka 事务
Kafka 中的事务与数据库的事务类似,Kafka 中的事务属性是指一系列的 Producer 生产消息
和消费消息提交 Offsets 的操作在一个事务中,即原子性操作。对应的结果是同时成功或者
同时失败。
8.Kafka 事务应用场景
在 Kafka 事务中,一个原子性操作,根据操作类型可以分为 3 种情况。情况如下:
1)只有 Producer 生产消息,这种场景需要事务的介入。Producer 多次发送消息可以封装成
一个原子性操作,即同时成功,或者同时失败;
2)消费消息和生产消息并存,需要事务介入。消费者&生产者模式下,因为 Consumer 在
Commit Offsets 出现问题时,导致重复消费消息,Producer 也可能重复生产消息。需要将
这个模式下 Consumer 的 Commit Offsets 操作和 Producer 一系列生产消息的操作封装成一
个原子性操作。
3)只有 Consumer 消费消息,这种操作在实际项目中意义不大,和手动 Commit Offsets 的结
果一样,而且这种场景不是事务的引入目的
9.结合业务解决 kafka 幂等性(扩展)
1. 数据写入数据库,根据主键查询,如果数据不存在就插入,如果存在就更新。
2. 数据写入 redis,每次都是 set 操作,天然幂等性。
3. 如果非上述场景,生产者给每条消息全局唯一 id,消费每条数据的时候去查一下 redis,
如果没有查到就可以消费,同时 id 写入 redis;如果查到了就丢弃掉,不做任何操作。
欢迎来撩 : 汇总all

