
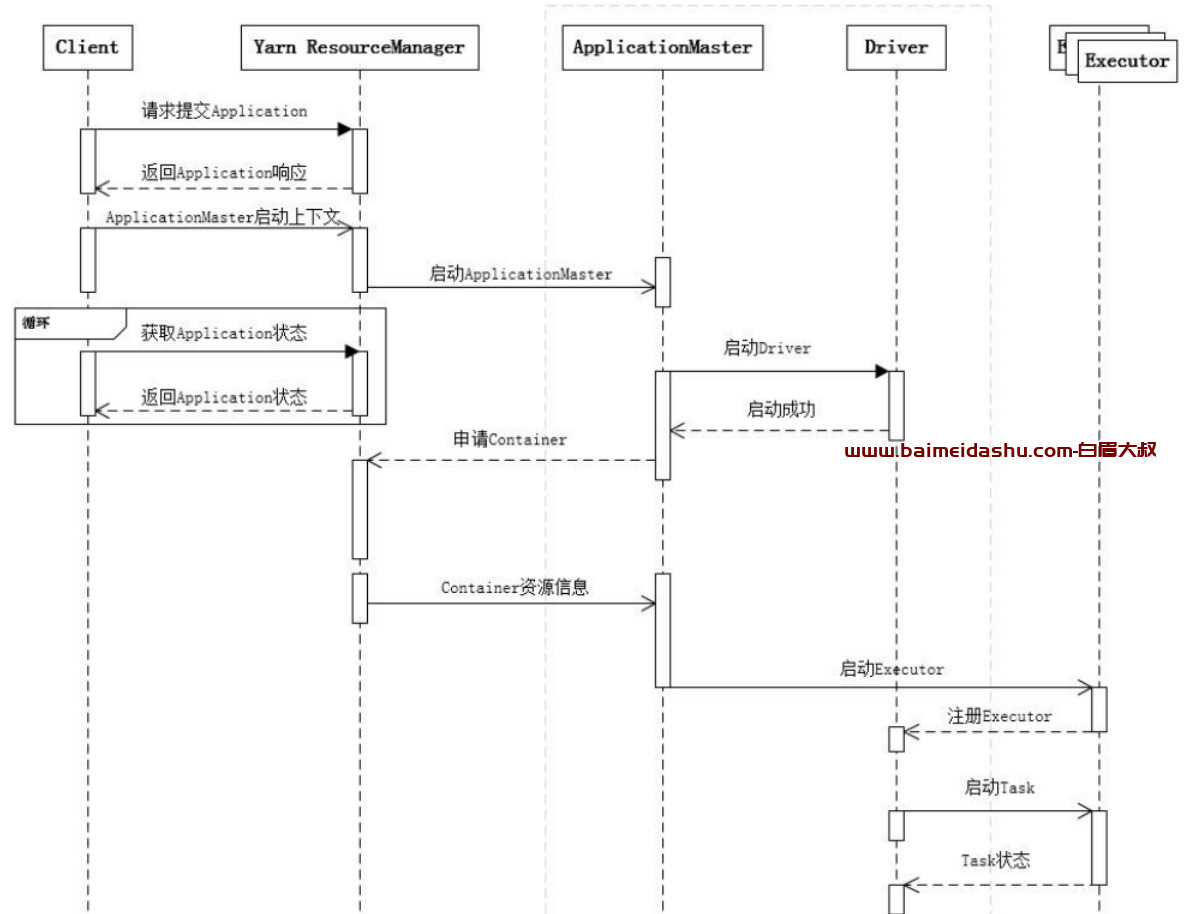
1.提交一个 Spark 应用程序,首先通过 Client 向 ResourceManager 请求启动一个 Application,
同时检查是否有足够的资源满足 Application 的需求,如果资源条件满足,则准备ApplicationMaster 的启动上下文,交给 ResourceManager,并循环监控 Application 状态。
2.当提交的资源队列中有资源时,ResourceManager 会在某个 NodeManager 上启动
ApplicationMaster 进程,ApplicationMaster 会单独启动 Driver 后台线程,当 Driver 启动后,ApplicationMaster会通过本地的RPC连接Driver,并开始向ResourceManager申请Container
资源运行 Executor 进程(一个 Executor 对应与一个 Container),当 ResourceManager 返回 Container 资源,则在对应的 Container 上启动 Executor。
3.Driver 线程主要是初始化 SparkContext 对象,准备运行所需的上下文,然后一方面保持与
ApplicationMaster 的 RPC 连接,通过 ApplicationMaster 申请资源,另一方面根据用户业务逻辑开始调度任务,将任务下发到已有的空闲 Executor 上。
5.当 ResourceManager 向 ApplicationMaster 返回 Container 资源时,
ApplicationMaster 就尝试在对应的 Container 上启动 Executor 进程,Executor 进程起来后,会向 Driver 注册,注册成功后保持与 Driver 的心跳,同时等待 Driver 分发任务,当分发的任务执行完毕后,将任务状态上报给 Driver。
Driver 把资源申请的逻辑给抽象出来,以适配不同的资源管理系统,所以才间接地通过ApplicationMaster 去和 Yarn 打交道。
Client 只管提交 Application 并监控 Application 的状态。
对于 Spark 的任务调度主要是集中在两个方面: 资源申请和任务分发,其主要是通过ApplicationMaster、Driver 以及 Executor 之间来完成
欢迎来撩 : 汇总all

