小模型需要微调,
## 什么时候需要 Fine-Tuning
1. 有私有部署的需求
2. 开源模型原生的能力不满足业务需求
举例:
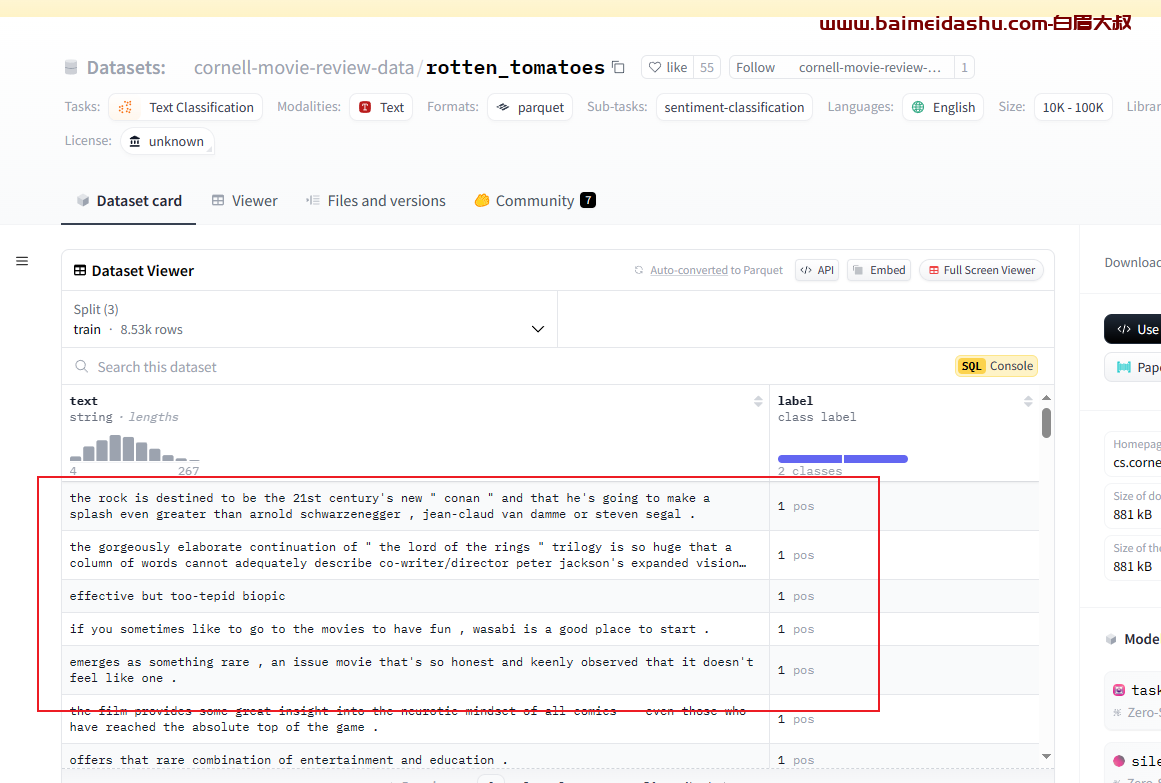
- **情感分类**
- 输入:电影评论
- 输出:标签 \['neg','pos'\]
- 数据源:https://huggingface.co/datasets/rotten_tomatoes就是更具评论数据, 判断是积极评论,还是消极评论
2-流程:
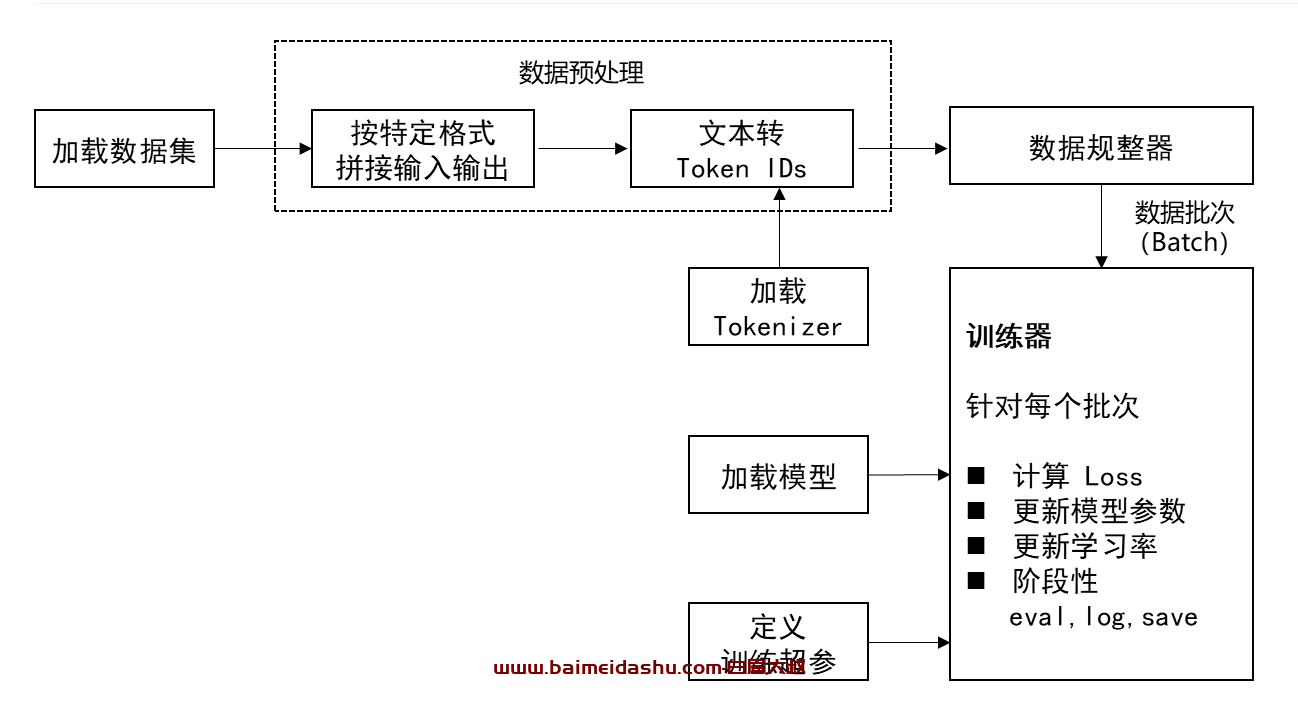
数据集: 就是告诉大模型,我给你输入A ,你要输出B 。 就是训练样本
数据预处理:就是把文本转化为 向量 ,也就是 token ,文本转ID 需要借助一个工具 Tokenizer
加载模型: 就是我们要用的大模型
定义训练超参: 就是准备我们大模型需要的配置文件,
数据规整器: 比如,我们训练1万条数据, 肯定需要分批给的,比如一次发8条,16条,32条。 具体多少,需要根据你的显卡大小来定。 采用随机采样。
训练器:(最核心的) huggingface 已经封装好了。
什么是超参:
ax +by 这是模型的参数。比如网络有多少层, 每层多大,等的呢个,这些也是参数, 但是为了跟ax+by 区别,就叫做超参。

微调的化这些
我们用代码来实操一下:
1. 导入相关库
import datasets
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel
from transformers import AutoModelForCausalLM
from transformers import TrainingArguments, Seq2SeqTrainingArguments
from transformers import Trainer, Seq2SeqTrainer
import transformers
from transformers import DataCollatorWithPadding
from transformers import TextGenerationPipeline
import torch
import numpy as np
import os, re
from tqdm import tqdm
import torch.nn as nn2. 加载**数据集**
通过 HuggingFace,可以指定数据集名称,运行时自动下载
# 数据集名称
DATASET_NAME = "rotten_tomatoes"
# 加载数据集
raw_datasets = load_dataset(DATASET_NAME)
# 训练集
raw_train_dataset = raw_datasets["train"]
# 验证集
raw_valid_dataset = raw_datasets["validation"]
3. 加载**模型**
通过 HuggingFace,可以指定模型名称,运行时自动下载
gpt2 比较小,等1-2分钟就可以跑试验了, 结构上个GPT4 没差别,只是参数少。
# 模型名称
MODEL_NAME = "gpt2"
# 加载模型
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,trust_remote_code=True)4. 加载 **Tokenizer**
通过 HuggingFace,可以指定模型名称,运行时自动下载对应 Tokenizer
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME,trust_remote_code=True)
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
tokenizer.pad_token_id = 0其他:
# 其它相关公共变量赋值
# 设置随机种子:同个种子的随机序列可复现
transformers.set_seed(42)
# 标签集
named_labels = ['neg','pos']
# 标签转 token_id
label_ids = [
tokenizer(named_labels[i],add_special_tokens=False)["input_ids"][0]
for i in range(len(named_labels))
]
开始:
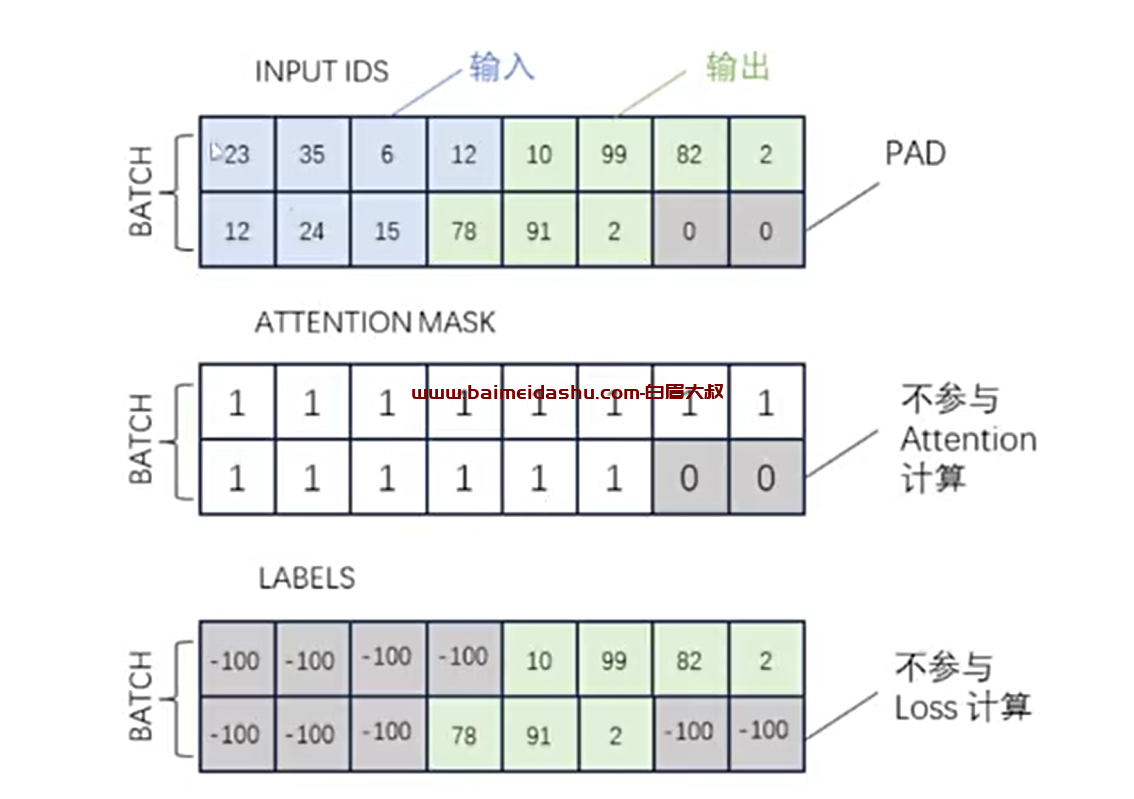
简单理解:
实际带入模型计算的是三个矩阵(tensor)
经过拼接和 PADDING 的输入输出 Token 序列
Attention Mask 序列,标识出 1 中的有效 Tokens(用于 Attention 计算)
Labels 序列,标识出 1 中作为输出的 Tokens(用于 Loss 计算)
https://www.zhihu.com/xen/market/training/training-video/1799089002780954627/1799089004433506307?education_channel_code=ZHZN-cd8085beea05e6d

欢迎来撩 : 汇总all