大家好,我是你的好朋友白眉大叔,今天这篇文章主要介绍一下 linux 正则表达式的入门,里边包含:
linux 正则表达式匹配字符串
linux 正则表达式以m开头以d结尾
以及linux 正则表达式匹配数字 等内容。
上篇文章 给大家介绍了 linux tar 打包压缩 , linux find命令
这些都是基础的知识,感兴趣的可以去参考一下。
BRE(基础正则表达式)只承认的元字符有^ $ . [ ] * 其他字符识别为普通字符;\(\)
ERE(扩展正则表达式)则添加了( ) { } ? + | 等
只有在用反斜杠"\"进行转义的情况下,字符( ) { }才会在BRE被当作元字符处理,而ERE中,任何元符号前面加上反斜杠反而会使其被当作普通字符来处理。
一、 什么是正则表达式
首先正则表达式 是为了处理大量的文字 ,文本,字符串,而定义的一套规则。 你就把它当做数学里的一个函数也可以。
通过定义一些 特殊符号的规则, 我们能够快速的过滤,替换,或者找到 我们需要的字符串内容。
你可以想一下,每天互联网上的上网日志,那么多内容,怎么从里边找到我们需要的内容呢?
可以这么简单的理解:
正则表达式就是 为了处理大量的字符串 而定义的一套规则, 它每次处理都是以行为单位, 一次处理一行 。
正则表达式- regular expression (RE)
案例: 1.txt
I am baimeidashu teacher!
I teach linux.
test
I like badminton ball ,billiard ball and chinese chess!
my blog is http: blog.51cto.com
our site is http:www.baimeidashu.com
my qq num is 593528156
aaaa,
not 572891888887.
^^^^^^^^66$$$$$$$^^^$$
baimeidashubaimeidashubaimeidashu
(1)以 某个字符开头
^这个符号代表 以什么为开头的意思
比如 我想找 以 not 为开头的那一行,怎么找呢?
grep '^not' 1.txt

(2)以某个字符结尾:
$ 这个符号代表 以 某个 字符结尾
比如: 找到以 156结尾的行
[root@baimeidashu /home]#grep '156$' 1.txt

(3)找到空行 ^$
^$ 这2个连在一起代表 过滤文件的空行
[root@baimeidashu /home]#grep '^$' 1.txt

我们可能不明显看出来,教给你个 参数 grep -v 是 取反的意思,
比如我们过滤空行看不出来, 取个反,就是 非空的行都出来。
[root@baimeidashu /home]#grep -v '^$' 1.txt

(4) 任意一个字符 .
点 . 代表过滤任意一个字符, 不会匹配到空行

grep -o : 代表 显示过程 (only matching )
grep -v : 带表取反
-v Invert the sense of matching, to select non-
matching lines. (-v is specified by POSIX.)
案例: 查找文件内以 . 结尾的行
[root@baimeidashu /home]#grep '\.$' 1.txt

来个面试题:
统计 /etc/paswd 单个字母每个出现了多少次
cat /etc/passwd |tr "[0-9:/x]" " "|grep -o .|sort|uniq -c|sort -rn|head

面试题2:
统计 /etc/passwd 每个单词出现了多少次
cat /etc/passwd | tr "[0-9:/x]" " "| xargs -n1|sort|uniq -c|sort -rn |head

(5) * 代表 前一个字符连续出现了0次或0次以上

单纯使用没有意义。
(6).* 代表 任何符号,包含空行
第二坑 正则的贪婪匹配 .* 所有符号 任何符号 连续出现的字符 有多少匹配多少
[root@baimeidashu /home]#grep '^.*m' 1.txt

[abc] 相当于是一个符号 每次匹配1个字符 找出包含a或b或c
一次找一个字符

[root@baimeidashu /home]#grep '[a-Z0-9]' 1.txt

第三坑 神奇的[] 在空括号里的符号 大部分没有特殊的含义 写什么找什么
[] [abc] 相当于是一个符号 每次匹配1个字符 找出包含a或b或c
一次找一个字符
grep '[a-Z,0-9]' 1.txt
测试以.和!和空格结尾
[root@baimeidashu /home]#grep '[.! ]$' 1.txt

括号:
第2部分: 扩展正则
grep -E
或者 egrep '过滤的内容' fiel
+ 前 一个字符连续出现1次或1次以上
[] 与 + 结合使用过滤连续的内容

过滤连续的a-z字母
[root@baimeidashu /home]#egrep '[a-z]+' 1.txt

(1 )| 扩展正则表达式 或者的意思

案例:
/etc/ssh/ssh_config 排除文件中的#和空行
[root@baimeidashu /home]#cat /etc/ssh/ssh_config |egrep -v '^$|^#'

(2) { }
第一种方法 {n,m}前一个字符至少连续出现n次 最多出现m次
[root@baimeidashu /home]#egrep '8{1,3}' 1.txt

第二种方法8{3} 最多显示多少次

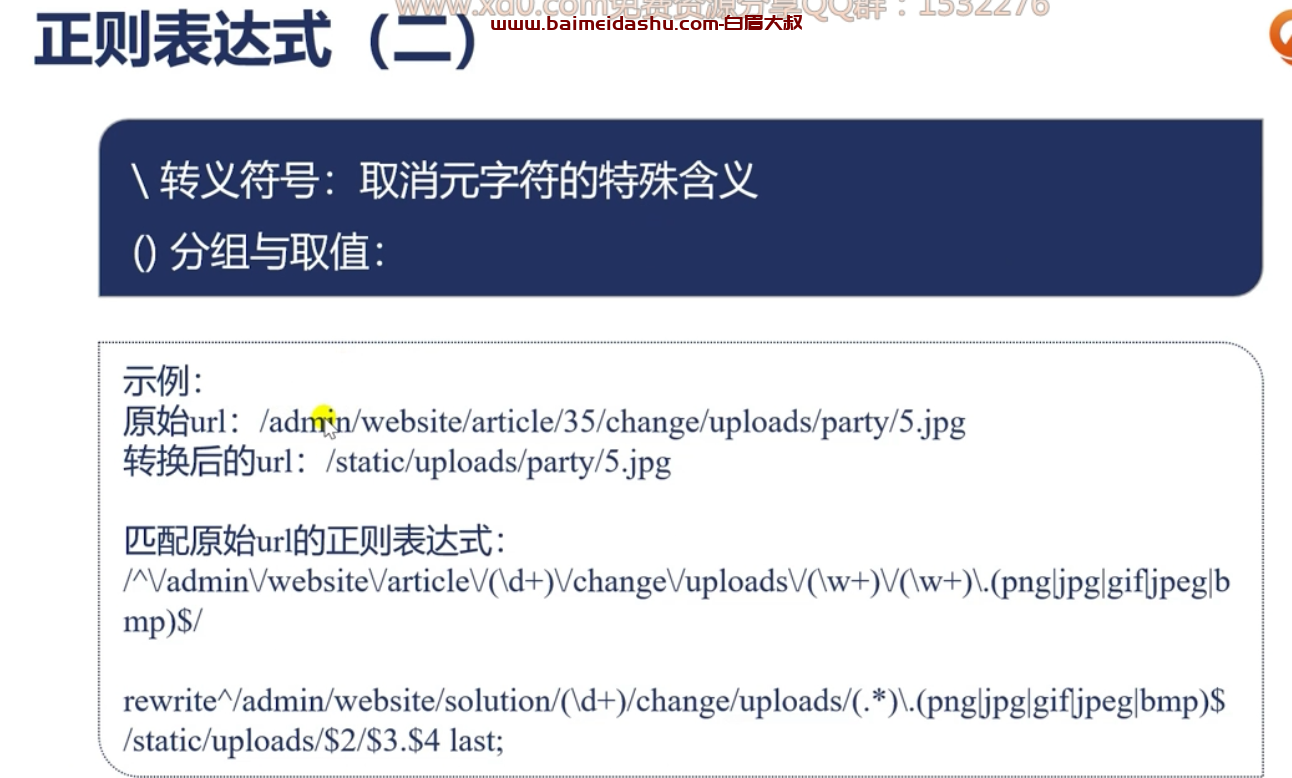
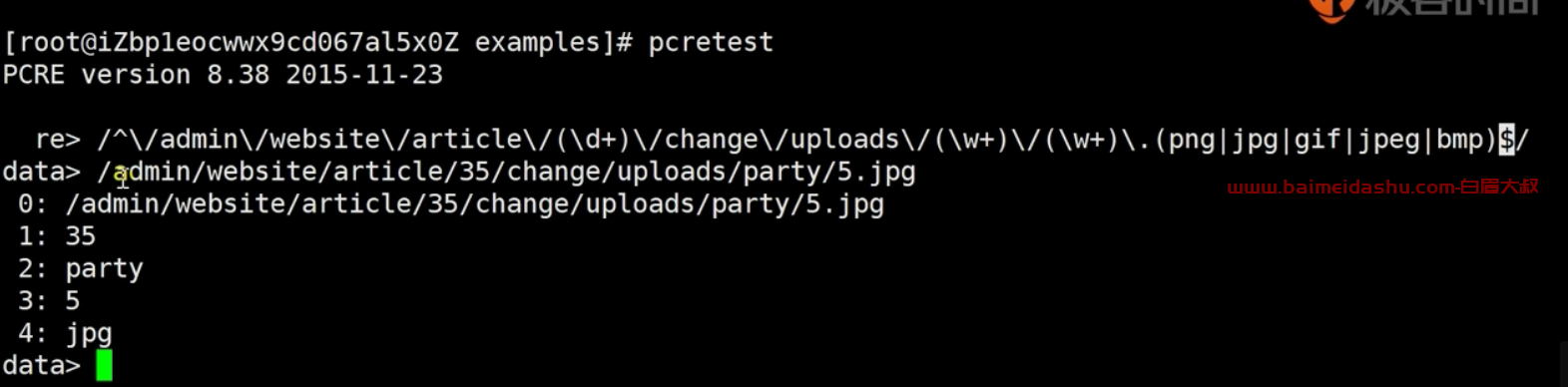
(3) ()表示一个整体, 反向引用 / 后向引用



总结:
欢迎来撩 : 汇总all