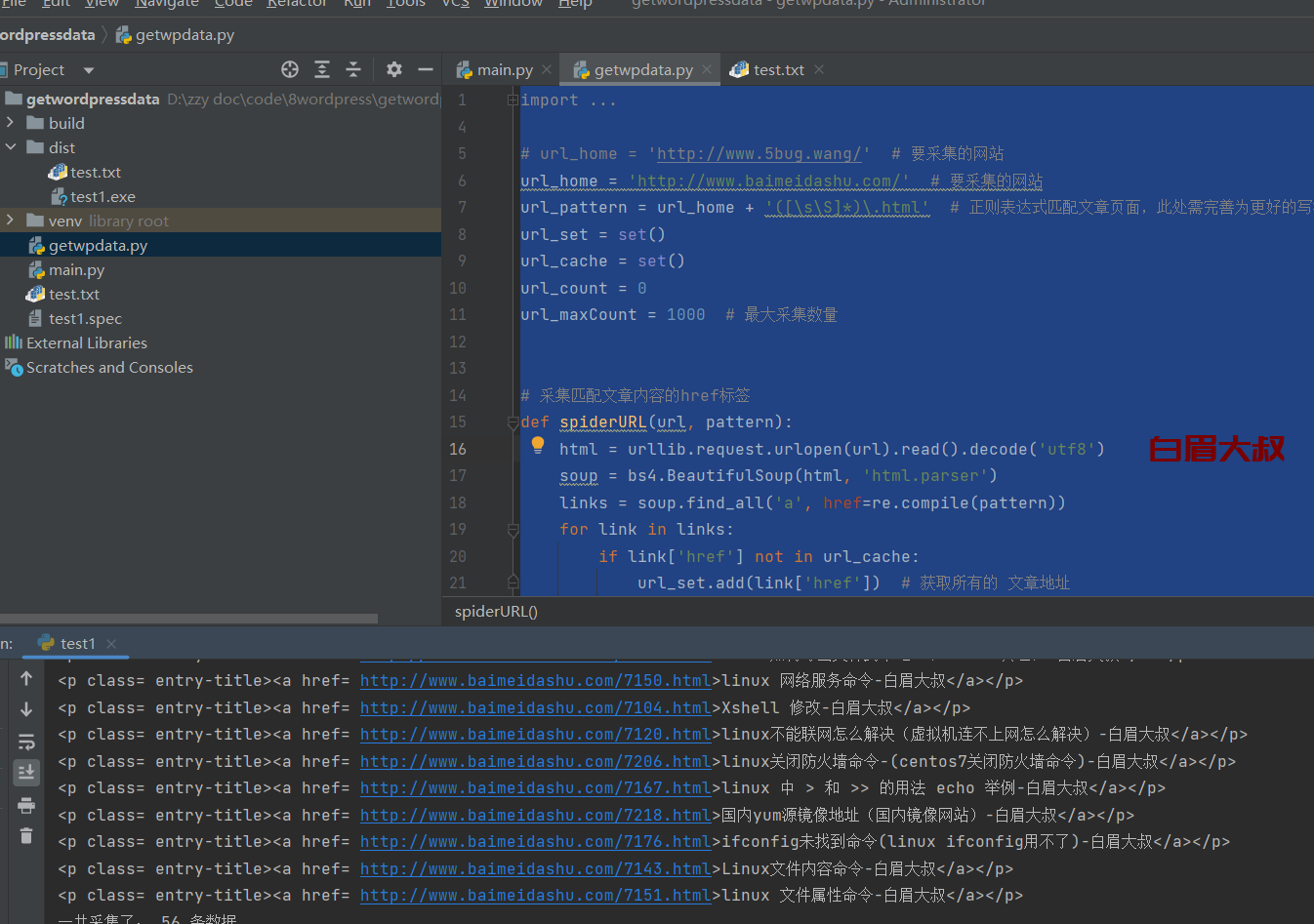
import re
import bs4
import urllib.request
# url_home = 'http://www.5bug.wang/' # 要采集的网站
url_home = 'https://www.baimeidashu.com/' # 要采集的网站
url_pattern = url_home + '([\s\S]*)\.html' # 正则表达式匹配文章页面,此处需完善为更好的写法
url_set = set()
url_cache = set()
url_count = 0
url_maxCount = 1000 # 最大采集数量
# 采集匹配文章内容的href标签
def spiderURL(url, pattern):
html = urllib.request.urlopen(url).read().decode('utf8')
soup = bs4.BeautifulSoup(html, 'html.parser')
links = soup.find_all('a', href=re.compile(pattern))
for link in links:
if link['href'] not in url_cache:
url_set.add(link['href']) # 获取所有的 文章地址
return soup
# 采集的过程 异常处理还需要完善,对于一些加了防采集的站,还需要处理header的,下次我们再学习
spiderURL(url_home, url_pattern)
while len(url_set) != 0:
try:
url = url_set.pop()
url_cache.add(url)
soup = spiderURL(url, url_pattern)
title = soup.find('title').get_text()
# print(title)
# print(url)
'''
<p class="entry-title"><a href="https://www.baimeidashu.com/7140.html">Linux文件目录命令(以及必须要掌握的几个目录)linux目录结构</a></p>
'''
ss = "<p class= " + "entry-title" + "><a href= "+ url +">" + title + "</a></p>"
print(ss)
file = open('test.txt', 'a')
file.write(ss)
file.write('\n')
file.close()
except Exception as e:
print(url, e)
continue
else:
url_count += 1
finally:
if url_count == url_maxCount:
break
print('一共采集了: ' + str(url_count) + ' 条数据')
欢迎来撩 : 汇总all