
YARN巡检
YARN 为 Hadoop 集群的上层应用,包括 MapReduce、Spark 等计算服务在内,提供了统一的资源管理和调度服务。每日早晚巡检 YARN 服务,主要检查资源池内主机的健康状态,保障 YARN服务可用性。
1.YARN CM 运行状态
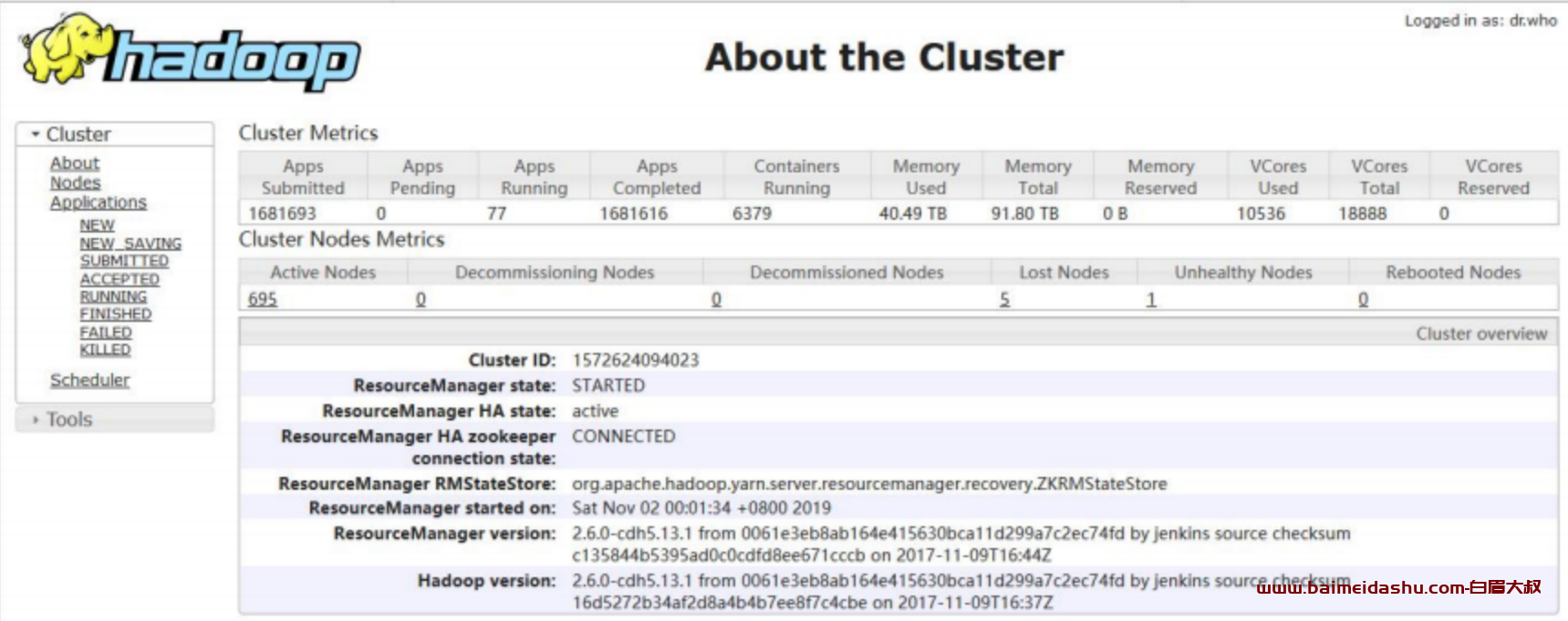
Yarn 集群,目前 Cloudera Manager 显示 6 个不良,16 个存在隐患
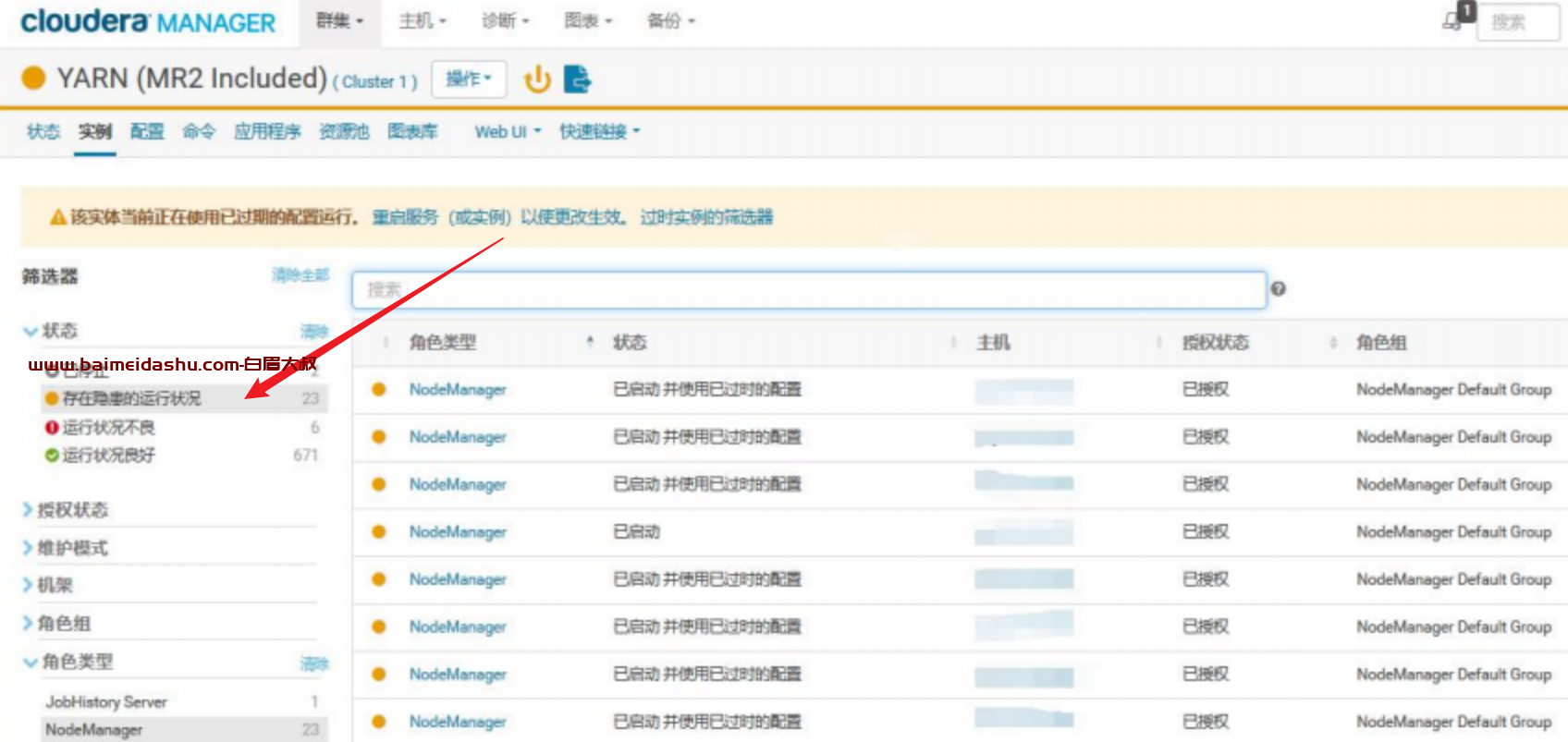
打开显示为不良的 NodeManager,这个节点有坏盘正在报修阶段
查看存在隐患的 NodeManager
查看正在运行的 Container 与总核数的差距
查看是否有大量失败的 Container,目前很少
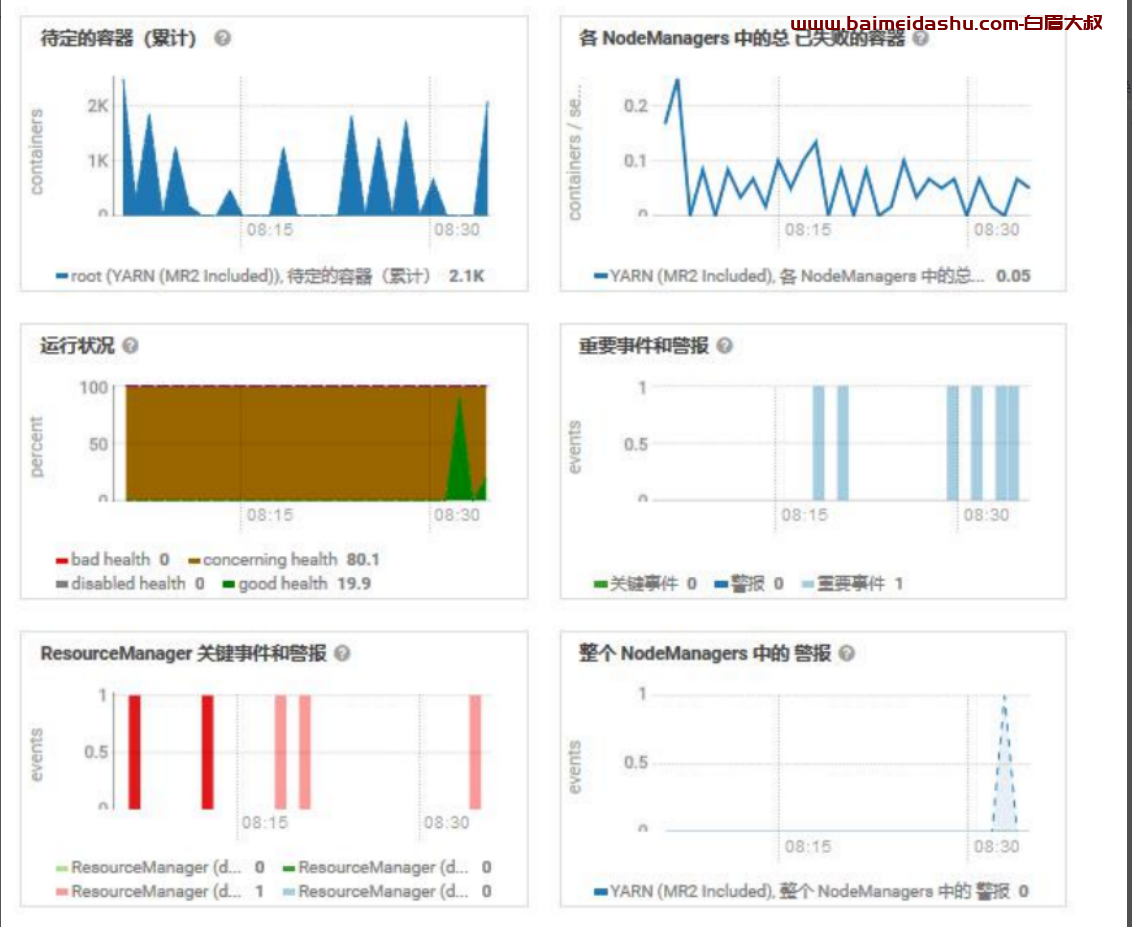
查看 resourcemanager 高可用状态,良好
查看 resourcemanager 监控指标,内存充足,待定的 Container 持续负载不高
JVM 堆栈,没有异常
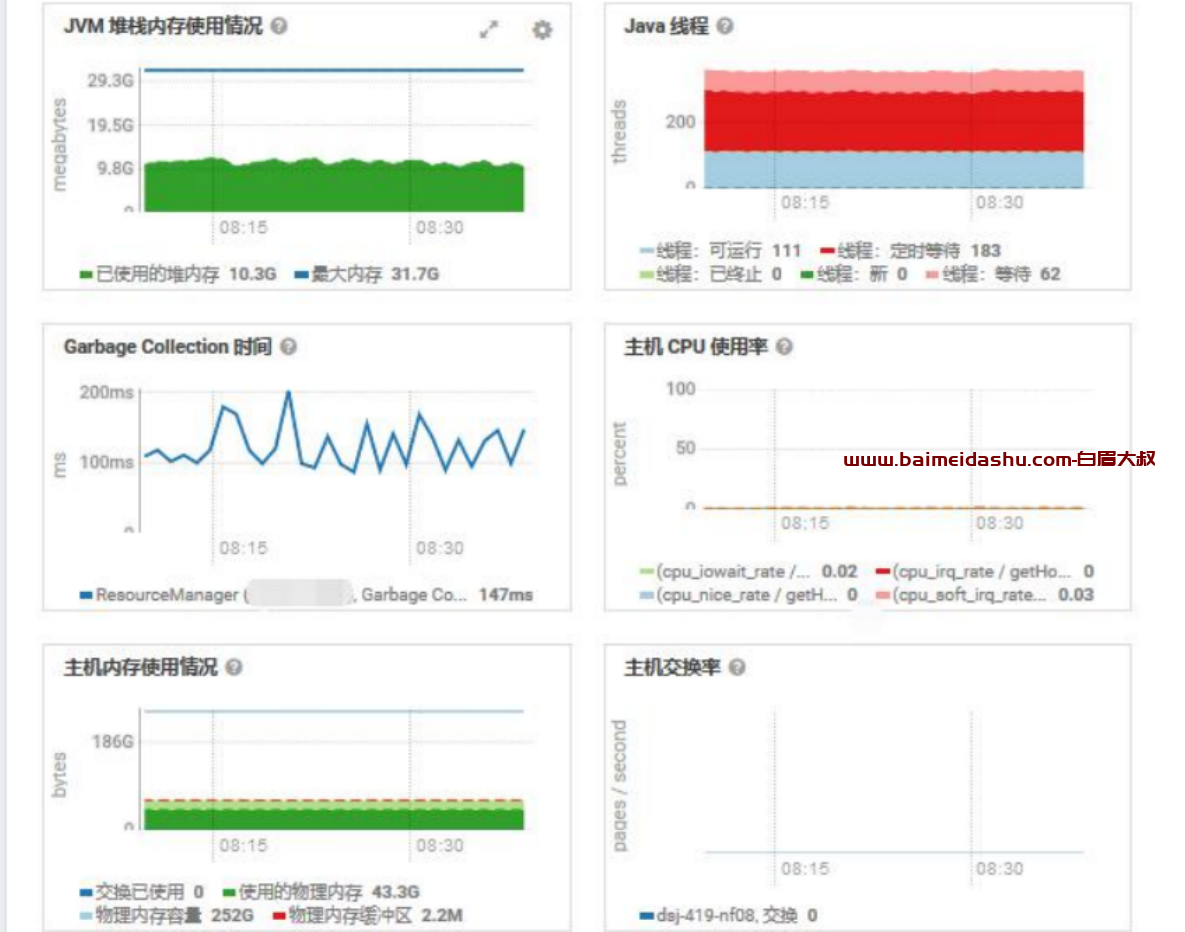
查看内存、磁盘情况,内存充足,磁盘延迟低
2.YARN WEB UI 运行状态
查看集群整体情况,发现 5 个 LOST 节点,1 个不健康节点
1 个不健康节点是有坏盘情况,已经进去报修阶段
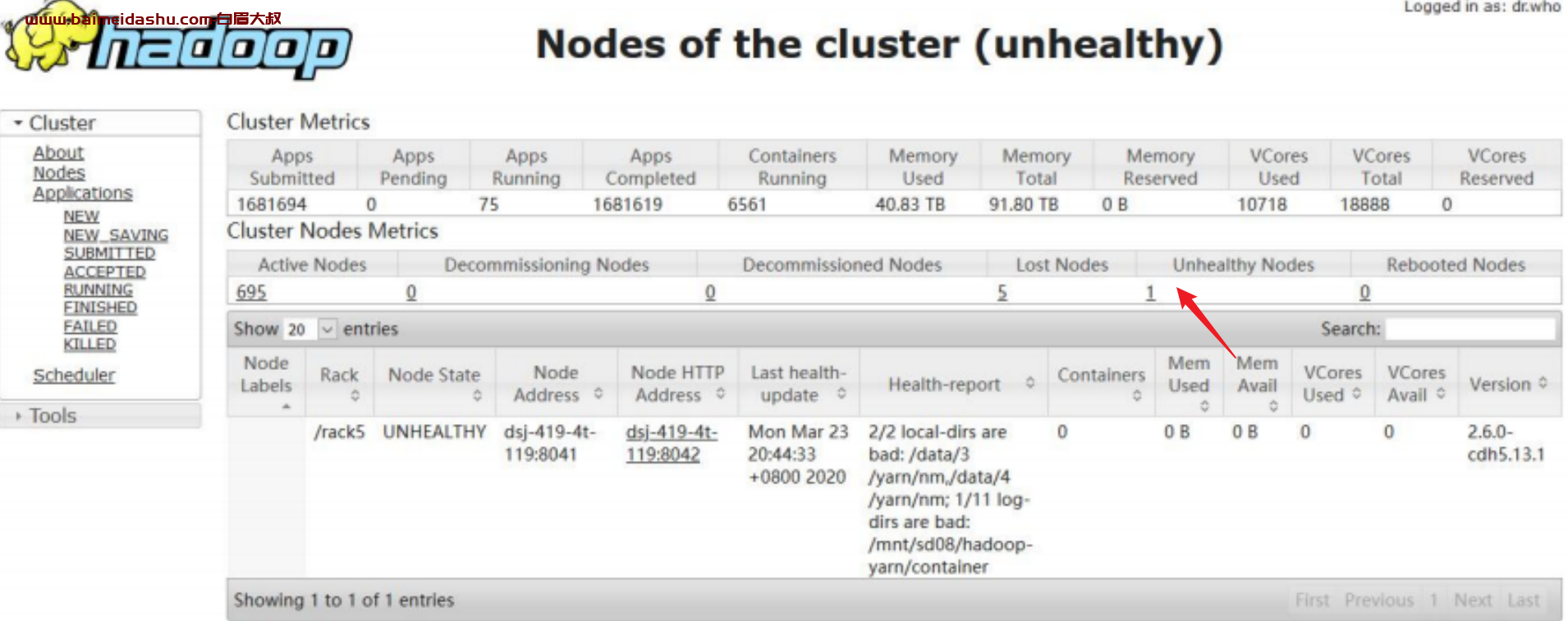
5 个 Lost Nodes 是因为几个主机总是问题以及 IAAS 测正在查看
查看资源队列资源使用情况,因为我是晚上 8 点截的图,是低峰期,所以使用资源不多
3.YARN/MR 关键性能指标
各个 NodeManager 的 GC 时间
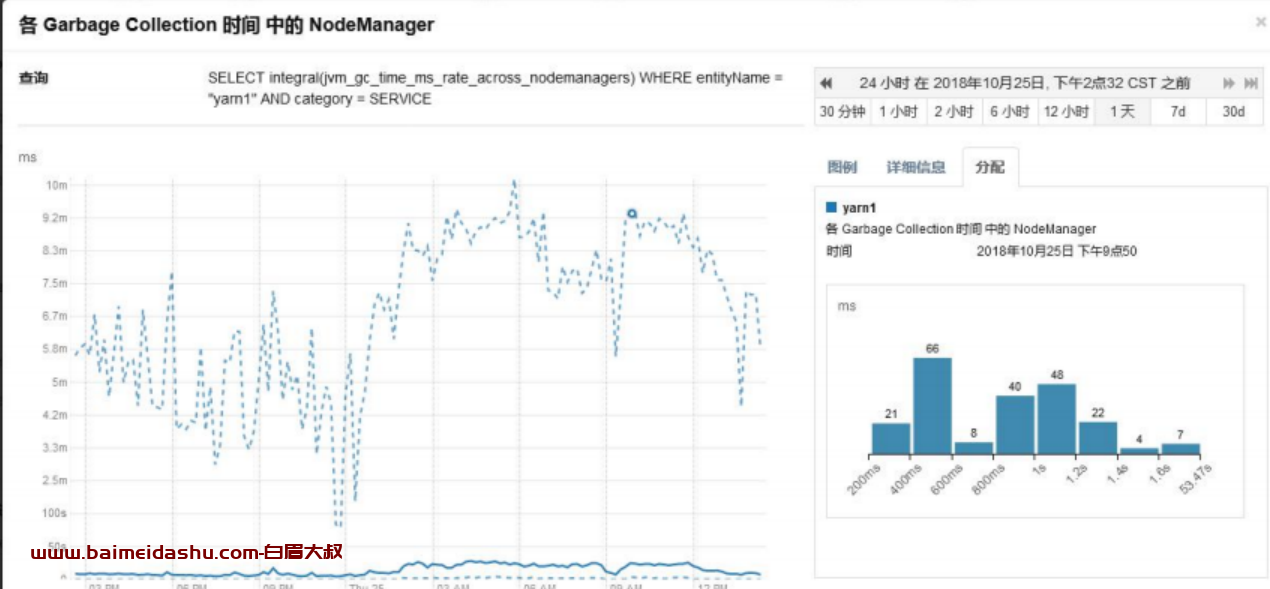
gc 时间基本在几 ms,gc 正常。
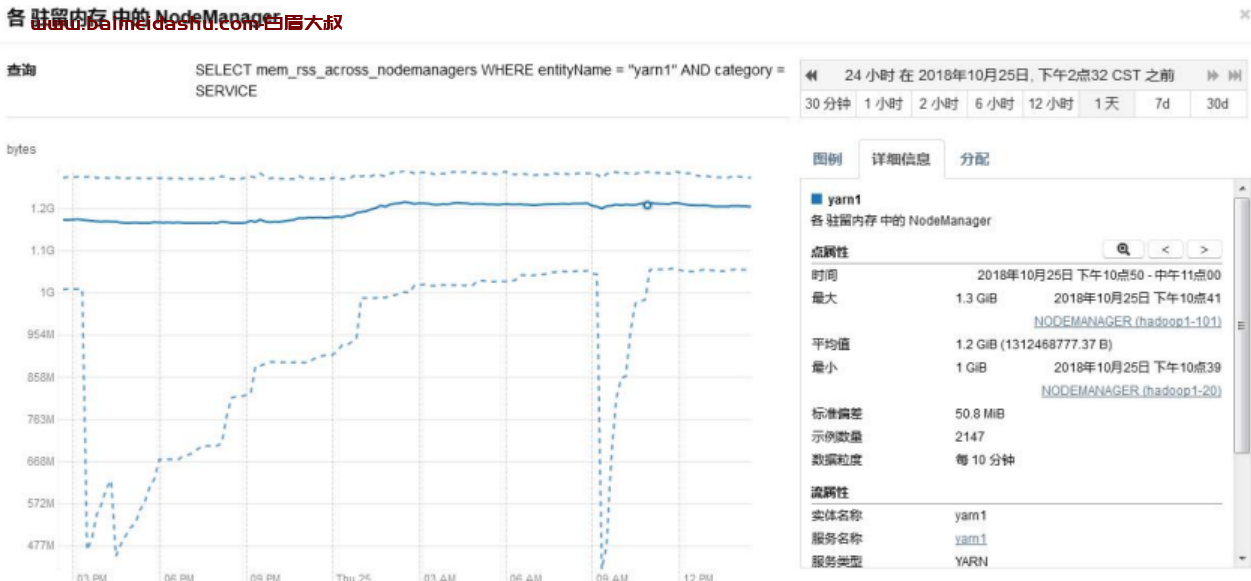
NodeManager 驻留内存
NodeManager 驻留内存为 1G 左右,因此建议提升 NodeManager 内存。
集群每秒完成的任务数
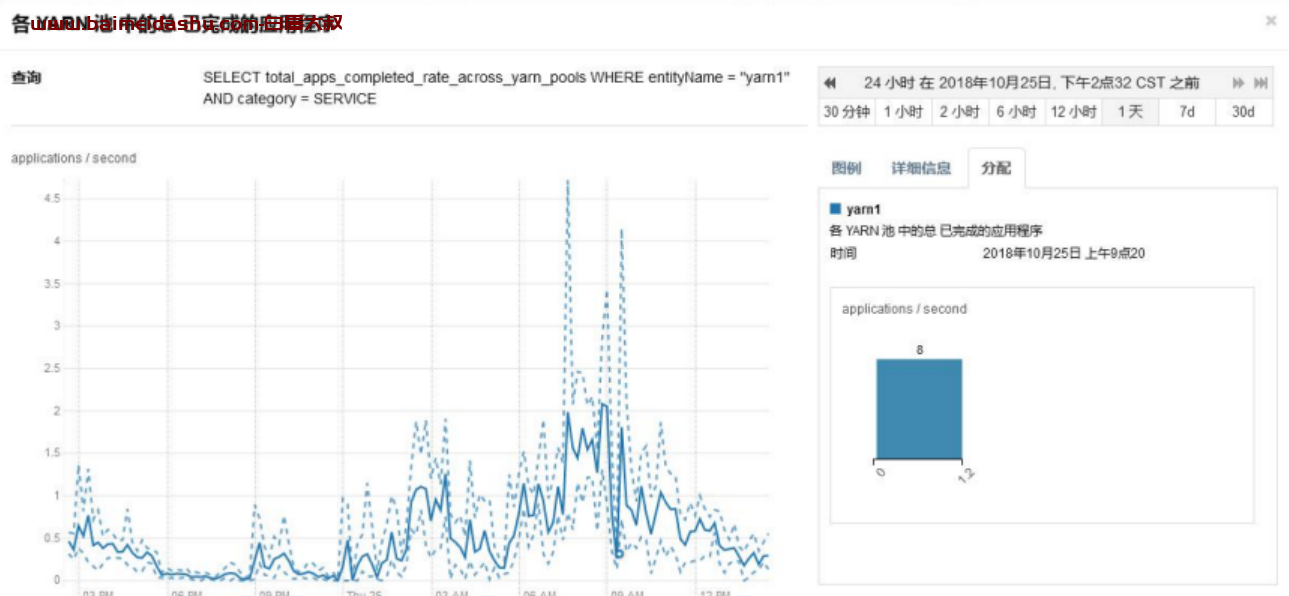
每秒完成 1.5 个任务。
1.存在问题
集群资源使用率较低
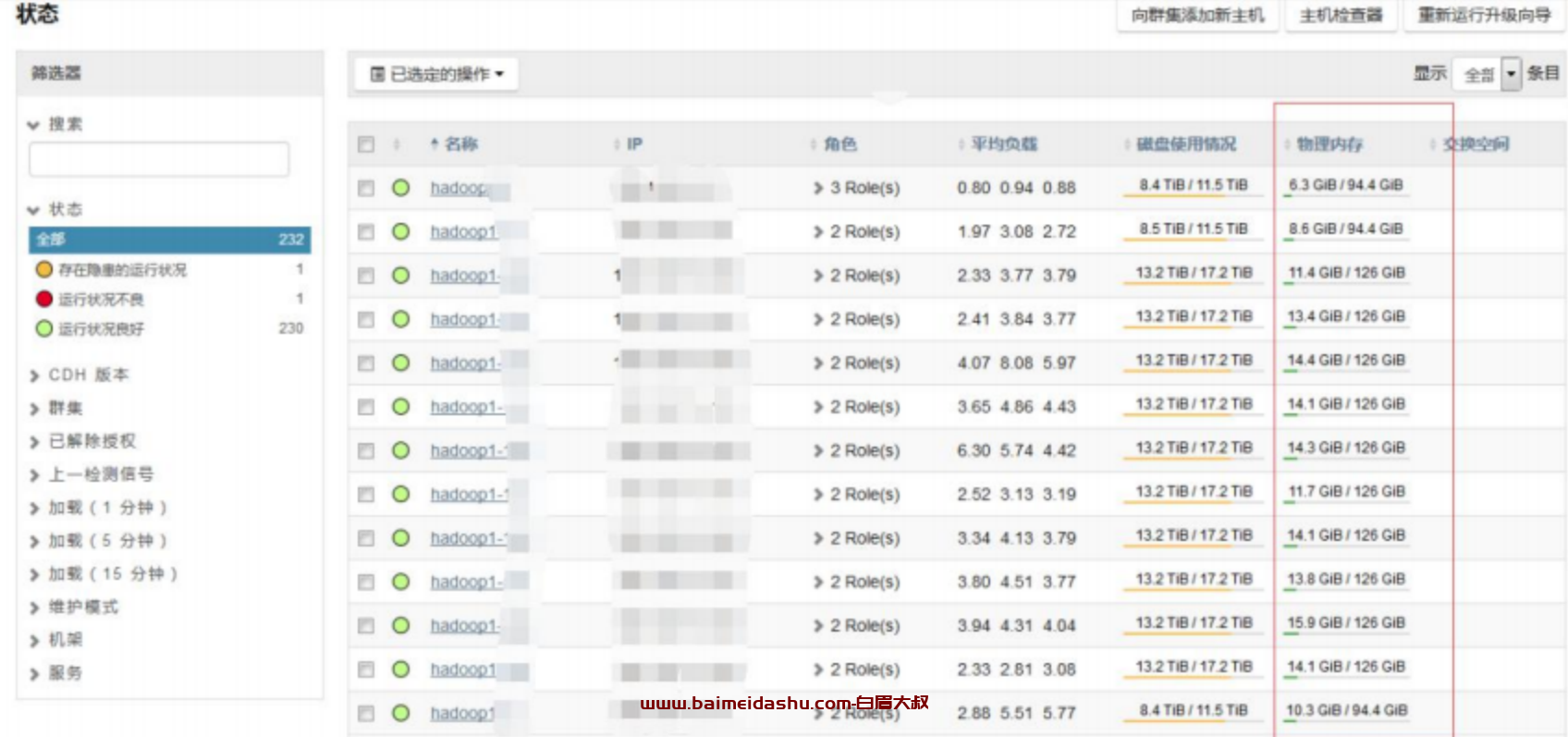
集群节点内存使用,节点普遍内存使用都只有 10G 左右。
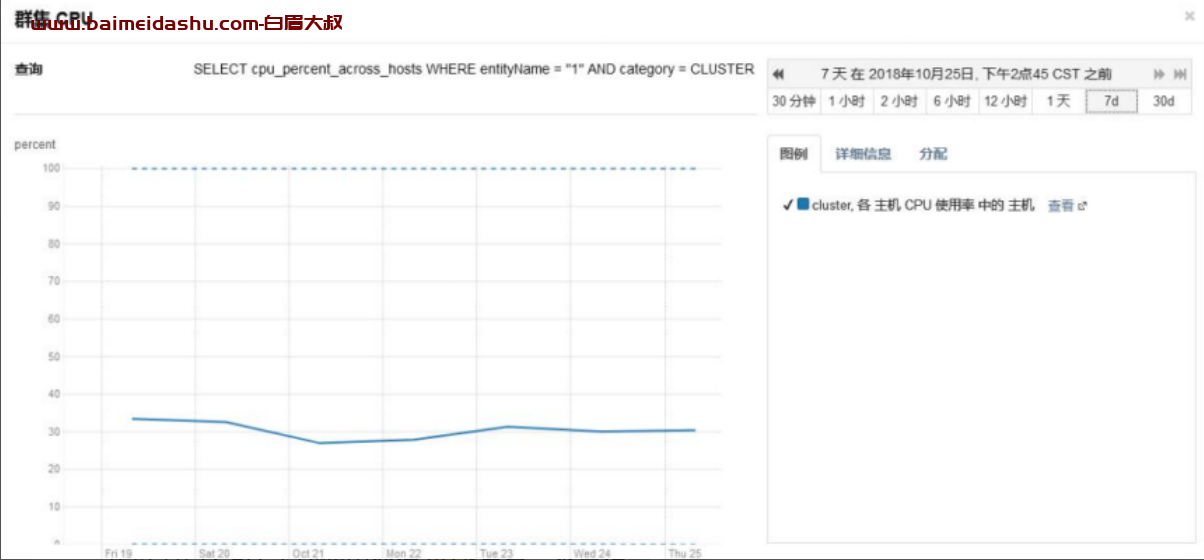
集群节点 CPU 平均使用率在 40%左右,不算很高。
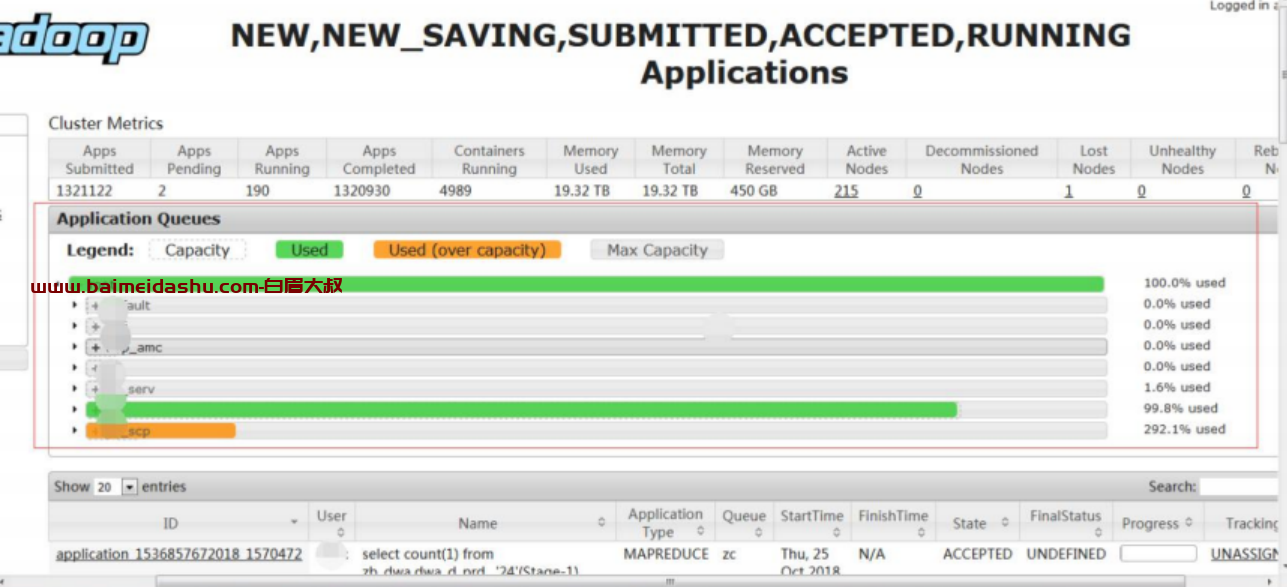
但是从 Yarn 的页面可以看到,Yarn 的集群使用率已经高达 100%
原因分析
Yarn 显示资源使用率达到 100%,而集群节点内存,CPU 等资源却使用不是
很高。Yarn 在配置时,通过设定每个 NodeManager 可以分配的 Container 内存,以及 CPU,来设定每个节点的资源。目前每个 NodeManager 配置了 120G,CPU 配置了 32VCore。
目前集群可能存在的问题是,每个 Container 分配的资源过高,实际任务并不需要这么多资源,从而出现了资源被分配完,但是使用率低的情况。
建议方案
降低 Container 的内存分配,增加 Nodemanager 能够分配的 Vcore 数。
配置如下:
yarn.nodemanager.resource.cpu-vcores: 48
2.Map 任务内存 mapreduce.map.memory: 1.5G
3.Reduce 任务内存 mapreduce.reduce.memory.mb 1.5G
4.Map 任务最大堆栈 mapreduce.map.java.opts.max.heap 1.2G
5.Reduce 任务最大堆栈 mapreduce.reduce.java.opts.max.heap 1.2G不过注意,对于某些对于内存需求较高的任务,需要单独设定,保证不出现outofmemory 的情况
欢迎来撩 : 汇总all

